Updated: October 11th, 2025. GLM-4.6 via API on OpenRouter appears to be very slow. Try official Zhipu’s API instead.
Zhipu AI’s GLM-4.6 is the latest among open-weight large language models. It is a 357B-parameter sytem that is poised to rival proprietary giants in coding. Released in late September 2025, GLM-4.6 arrives as an open-weight model (MIT licensed) with an ambitious goal: deliver Claude-level performance at a fraction of the cost. This review takes a deep dive into GLM-4.6’s capabilities, how it stacks up against competitors like Moonshot’s Kimi K2–0905, OpenAI’s GPT-OSS-120B, DeepSeek V3.2, and Alibaba’s Qwen-3 Max Preview, and what early users and benchmarks are saying.
From GLM-4.5 to 4.6 — What’s New?
GLM-4.6 builds on a strong foundation (its predecessor GLM-4.5 was already a top open model) and introduces several major improvements:
- 200K Context Window: The context length expanded from 128K to 200K tokens, enabling the model to handle extremely long inputs and multi-step “agentic” tasks without losing track. This rivals or exceeds the context of many current models – for perspective, it can ingest entire codebases or lengthy documents in one go. In real terms, tasks like debugging a 50,000-line code project or maintaining conversation state over hours are now feasible.
- Superior Coding Skills: GLM-4.6 is explicitly tuned for coding. It demonstrates major gains on coding benchmarks and real-world programming tasks. Early adopters report that it produces not just correct code, but more polished, human-like outputs in front-end development and UI design. This suggests the model has “learned” best practices in code style and can generate aesthetically clean web layouts out-of-the-box.
- Advanced Reasoning & Tool Use: The new model shows a clear improvement in reasoning, especially when it engages “thinking mode” with tools. GLM-4.6 can invoke tools (like web search, code execution, calculators) during its responses, enabling it to solve complex problems more effectively. This agentic capability — chaining reasoning steps with external tool calls – was tricky for many models, but GLM-4.6 handles it naturally. As a result, it can answer math word problems, perform data analysis, or browse the web for facts within a single session.
- More Capable Agents: In autonomous agent frameworks (e.g. running in a loop to accomplish goals), GLM-4.6 integrates more smoothly than before. It’s better at using tools like terminal commands or search in those settings. Its decision-making in multi-turn tasks is improved, making it a strong backend for AI agents that write code, scrape data, or interact with software.
- Refined Writing & Alignment: Though marketed as a coding-first model, GLM-4.6 has also been refined for general writing. It adopts a more natural, human-like style, is less verbose and “robotic,” and even performs well in creative or role-play prompts. User feedback notes that it’s less likely to produce awkward phrasing. In fact, on at least one user-driven leaderboard, GLM-4.6 ranks #1 in creative writing among open models — a testament to its well-rounded training.
Notably, GLM-4.6 retains open access: developers can download the full weights and run it locally (with sufficient GPU muscle), or access it via API or through Zhipu’s own chat interface. There one can even create PowerPoint-style presentation slides. These are the slides I made with GLM-4.6 for this article.
Benchmark Performance: Coding, Math, and More
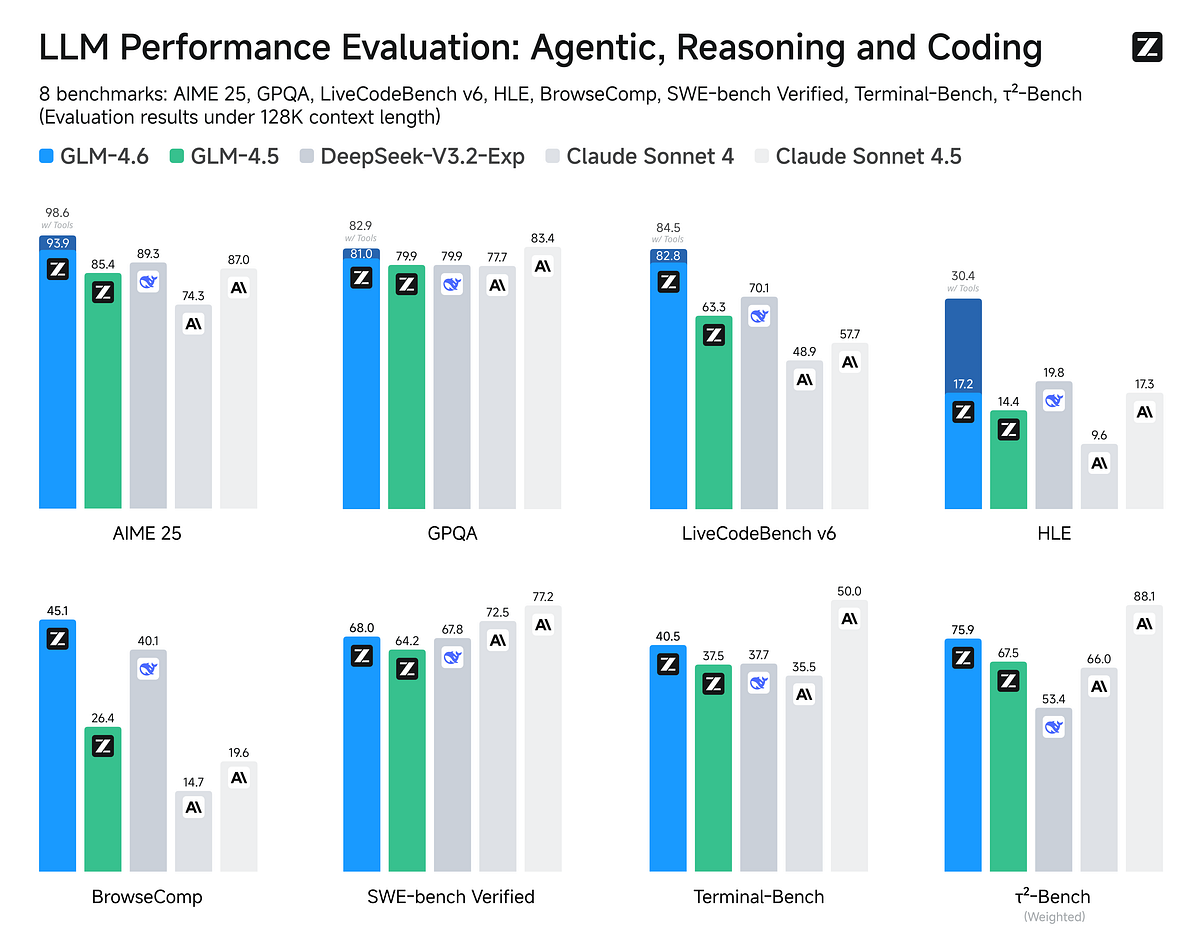
How does GLM-4.6 actually perform? Zhipu evaluated it on eight public benchmarks spanning coding, reasoning, and agent tasks. The results are impressive, GLM-4.6 shows clear gains over GLM-4.5 across the board, and even outperforms leading domestic and international models in many areas. Let’s break down some key benchmarks:

Coding Benchmarks – LiveCodeBench & SWE: On the LiveCodeBench v6 test (which involves writing, executing, and debugging code across languages), GLM-4.6 delivered a score of 82.8%, a huge jump from GLM-4.5’s 63.3%. This essentially matches the level of Anthropic’s Claude 4 (mid-80s on this benchmark), making GLM-4.6 one of the best coding models available. Meanwhile, Moonshot’s Kimi K2–0905 , itself a coding specialist with a 1 trillion-parameter MoE architecture , was trailing here in the upper 70s%. And OpenAI’s GPT-OSS-120B, which is a general-purpose model, scored about 83%. In practice, GLM-4.6’s coding prowess is evidenced by it generating fully functional, clean code. Developers testing it have noted noticeably better front-end outputs (HTML/CSS that looks professionally formatted) that required little manual polishing, whereas many models produce bare-bones solutions.

However, on the Software Engineering (SWE) Bench – Verified split (a benchmark having models debug and refactor real-world codebases), GLM-4.6 scores 68.0%, which is solid but not #1. Claude 4.5 Sonnet tops this benchmark at 77.2%. Kimi K2–0905, after its September update, is right around GLM’s level (internally Moonshot reported ~69.2% for K2–0905 on SWE Verified). GPT-OSS-120B scores a bit lower (~62%), reflecting that pure reasoning models can struggle with messy repository code. These results echo a common theme: Claude remains a gold standard in deeply understanding large codebases, but among open models GLM-4.6 and Kimi K2 stand at the top of the pack. The gap between them is narrow – within a few points – essentially a neck-and-neck in coding ability, with different strengths (Kimi sometimes edges GLM on structured code tasks, while GLM often produces more maintainable code).

Mathematical & Logical Reasoning – AIME & HLE: GLM-4.6 has made headlines with its performance on math-heavy reasoning tasks. On the challenging AIME 2025 competition exam (an advanced high-school math contest), GLM-4.6 scored 93.9% correct in standard mode. When allowed to fully utilize tools (e.g. run Python for calculations), it reached a staggering 98.6% accuracy – essentially solving all problems correctly. This surpasses even GPT-4-level performance and is nearly unprecedented. In fact, it’s only a hair behind the best closed models like GPT-5 on this test. By comparison, OpenAI’s GPT-OSS-120B achieved ~92.6%, and Claude 4.5 around 87%. DeepSeek’s V3.1-Terminus (with its “Thinking” mode) is also known to excel in math; it reportedly edged out Kimi K2 in some pure math challenges, likely scoring in the 90% range as well. Nonetheless, GLM-4.6 now ranks among the very top on math problem-solving — an impressive feat for an open model, suggesting superb chain-of-thought reasoning and/or effective tool use integration.

Another metric, HLE (Hard Logical Evaluation), further highlights GLM-4.6’s logical reasoning gains. GLM-4.6 scored 30.4% on HLE with tools, versus Claude 4.5’s 17.3%. HLE is a test of complex logical consistency (the kind of puzzles where the model must not contradict itself). GLM’s almost double score indicates a significant advantage in maintaining logical coherence – crucial for applications like legal reasoning or planning, where a single lapse breaks the solution. It appears Zhipu’s training focus on step-by-step reasoning paid off.
Agentic Tasks – Real-World Coding & Tool Use: Perhaps the most telling results come from CC-Bench (Coding Challenge Benchmark) v1.1, a novel evaluation where human evaluators had each model act as a developer inside a Docker environment to solve 70+ real-world tasks. These tasks included things like building a simple web app, writing a data analysis script, fixing bugs with unit tests — essentially simulating actual programming assignments. In this realistic agent setting, GLM-4.6 achieved a 48.6% win rate against Anthropic’s Claude 4 (almost parity). It outright won 50% of rounds against its predecessor GLM-4.5, showing just how much it improved. Against other open models the dominance was clear: GLM-4.6 won 64.9% of head-to-head trials vs DeepSeek-V3.1-Terminus, and 56.8% vs Kimi K2–0905. In plain terms, when put to work on multi-step coding jobs, GLM-4.6 was usually the victor among open models, and even nearly matched Claude 4’s prowess. This is remarkable, considering Claude (especially the new Sonnet series) was known for agentic abilities. It validates GLM-4.6’s design as a coding-first, tool-using AI. One factor here is efficiency — GLM-4.6 tends to solve tasks with far fewer back-and-forth messages. Evaluators noted it often produced a correct solution in one or two well-thought-out replies, whereas others rambled or iterated more. Data backs this: GLM-4.6 used ~15% fewer tokens than GLM-4.5 on average, and was 26% more token-efficient than Kimi K2, and 45% more than DeepSeek Terminus. Over long sessions, that efficiency compounds into faster completion and less cost.
Finally, in terms of knowledge and general QA: on the GPQA benchmark (Graduate-Level Problem QA, covering advanced science/academia questions), GLM-4.6 scored 82.9% with tools — essentially tied with Claude 4.5’s 83.4%. This suggests that GLM’s academic knowledge and reasoning are on par with Claude’s in this domain. Alibaba’s Qwen-3 Max Preview was known to be strong here as well (it reportedly had leading open-source scores on GPQA and the MMLU knowledge test), likely in the 80%+ range too. In other words, GLM-4.6 can hold its own on expert-level QA, indicating a broad and up-to-date training in science and facts — not just code.
How GLM-4.6 Stacks Up Against Competitors
GLM-4.6 enters a crowded field of large models. Here’s a look at its key rivals in late 2025 and how they compare:
Kimi K2–0905 (Moonshot AI): If GLM-4.6 is a coding-specialist open model, K2–0905 is perhaps its closest peer. Kimi K2 is an MoE-based behemoth — 1 trillion parameters total (with ~32B active per token) — and it too is tuned heavily for coding and agent tasks. The September “0905” release doubled K2’s context window to 256K tokens (snagging the context crown) and improved coding performance (SWE-Bench jumped from ~65% to ~69% for K2). In internal Moonshot tests, K2–0905 is shown nearly matching GPT-4 on some benchmarks, reflecting how far open models have come. In practice, K2 and GLM trade blows. Coding: On LiveCode-style tasks, GLM-4.6 appears to have a slight edge or equal footing, possibly owing to its better integration of tool use (K2 doesn’t have an explicit “thinking mode” toggle; it decides CoT depth implicitly). However, K2’s extensive coding fine-tuning shows in certain multi-step and front-end scenarios — for instance, Moonshot reports K2 often produces extremely clean UI code and even 3D graphics code, which aligns with user feedback that K2 “learned” design aesthetics. Reasoning: DeepSeek’s team observed that in pure logical or math puzzles, DeepSeek V3 in full reasoning mode could outscore K2 slightly, implying K2’s reasoning is strong but not unmatched. GLM-4.6’s huge AIME win suggests it may now surpass K2 on math. Real tasks: A revealing comparison had Kimi K2 and Alibaba’s Qwen-3 Coder tackle 15 complex coding projects — K2 solved ~93% while Qwen only ~47%. This underscores K2’s reliability and adherence to instructions. Compared to GLM, K2’s code output is similarly high-quality; one noted difference is K2 excels at following project conventions and producing test cases. GLM-4.6 is not far behind on those fronts and even beat K2 in the CC-Bench head-to-head. Bottom line: GLM-4.6 and Kimi K2–0905 are the two top open coding models right now. K2 boasts the larger scale and slightly better raw coding benchmark in some areas (plus a bigger context), but GLM-4.6’s toolkit (thinking+tools) and efficiency give it a practical edge. Crucially, GLM-4.6 is also much lighter to run — K2’s trillion-weight MoE is harder to deploy (though MoE gating mitigates it), whereas GLM’s 357B dense model has been optimized for faster inference (it can even achieve ~100+ tokens/sec generation on some hardware as users report).
GPT-OSS-120B (OpenAI): GPT-OSS is OpenAI’s surprise entry into open models (the “OSS” stands for open-weight). Released August 2025, GPT-OSS-120B is a 117B parameter Mixture-of-Experts model that OpenAI open-sourced under Apache-2.0. It’s essentially an “open GPT-4 mini” designed to run on a single high-end GPU, with about 5.1B parameters active per token. GPT-OSS was immediately a strong baseline: it achieves near-parity with OpenAI’s own GPT-4 mini on many reasoning tasks. In benchmarks, GPT-OSS scored 90.0% on MMLU, showing excellent general knowledge. On coding, its results were mixed — 83.2% on LiveCodeBench (very good), but only 62.4% on SWE-Bench. This tells us GPT-OSS can write and explain code well, but may falter in comprehending large existing codebases or producing robust patches (likely due to less specialized fine-tuning). Against GLM-4.6, GPT-OSS now looks a bit dated — GLM outperforms it on code benchmarks and matches/exceeds it on math. For instance, GPT-OSS scored 92.6% on AIME, which GLM-4.6 edged out. GPT-OSS does support tools and chain-of-thought, similar to GLM’s features, and is optimized for “reasoning mode” at different effort levels. But GLM-4.6’s larger size and specialized training give it the clear advantage. One should note GPT-OSS remains highly valuable: as an efficient 120B model, it’s much cheaper to host; its cost and speed are significantly better than GLM’s if resource is limited. In fact, OpenAI pitched GPT-OSS as ideal for single-GPU deployment, whereas GLM-4.6 really needs multi-GPU or TPU pods for full 200K context usage. So, for smaller-scale use or fine-tuning, GPT-OSS is appealing. In summary, GPT-OSS was the open reasoning leader of mid-2025, but GLM-4.6 has overtaken it in most categories (coding especially), albeit at the cost of being a bigger model.
DeepSeek R1.2 & V3.2-Exp (DeepSeek AI): DeepSeek models are known for their innovative “Thinking vs Non-thinking” modes — a switch to trade-off speed and depth. R1 was DeepSeek’s first-gen reasoning model, prized for reliability and low hallucination. R1.2 (May ’25) likely refers to an updated R1–0528 model. By late 2025, DeepSeek’s flagship is V3.1-Terminus and its experimental offshoot V3.2-Exp. Terminus introduced hybrid inference where you can explicitly request the model to think step-by-step; when cranked to full “ultra-think,” it achieved outstanding benchmark scores in logic and math – in some cases outscoring Kimi K2 on algorithmic problems. On coding benchmarks like LiveCodeBench, DeepSeek V3.1 (thinking mode) could sometimes surpass K2 as well, albeit with a lot of verbose reasoning. The newly released V3.2-Exp didn’t boost raw accuracy but halved the inference cost using sparse attention, making DeepSeek more efficient. Where does GLM-4.6 stand relative to DeepSeek? Zhipu’s blog coyly noted GLM-4.6 holds “competitive advantages” over DeepSeek-V3.2-Exp. Indeed, in CC-Bench real tasks, GLM beat DeepSeek Terminus ~65% to 35% of the time. The advantage likely comes in coding agent tasks — DeepSeek can solve tough problems but often in an overly meticulous way (e.g. writing a whole compiler for a simple parsing task). GLM-4.6 tends to produce more concise, practical solutions (aiming for usable code rather than theoretical perfection). Also, GLM is significantly faster per solution; DeepSeek’s ultra-thinking, while powerful, is slow and token-hungry (in one anecdote, it wrote hundreds of lines where GLM/Kimi wrote dozens). Bottom line: DeepSeek models remain excellent thinkers — for pure reasoning (like puzzle-solving or planning with no regard to time) they are contenders. But GLM-4.6’s more balanced approach yields higher throughput on complex tasks. For most users building applications, GLM’s style of reasoning (and its easy, automatic tool use) will be more effective than toggling DeepSeek’s modes. DeepSeek V3.2’s big win is efficiency — its API now costs 0.28¢ (non-cached) per million tokens, cheapest of the lot, thanks to sparse compute. That makes it attractive for cost-sensitive deployments, even if raw performance is slightly behind GLM.
Qwen-3 Max Preview (Alibaba): Qwen is Alibaba’s line of large models (previously Qwen-7B, 14B, etc., which were open-source as well). In 2025, Alibaba was testing Qwen-3 Max, a much larger model (rumored to be multi-hundred-billion parameters with Mixture-of-Experts of its own). The “Max Preview” was an early release version for evaluation. Reports showed Qwen-3 Max Preview was a formidable all-rounder — it posted leading open-source scores on benchmarks like LiveCodeBench, MMLU, and GPQA. In fact, prior to GLM-4.6, Qwen-3 Max (preview) might have been the top open model on the popular LMArena user leaderboard, particularly in knowledge and code. For example, Qwen scored so high on coding that it was essentially tied with GPT-4’s smaller variants. However, Alibaba’s own results indicated some quirks: Qwen-3 Max Preview excelled at certain tasks (e.g. legal reasoning) even more than the final Max release, while the final improved on math by +17%. Given that, it’s likely Qwen-3 Max’s performance on coding is comparable to GLM-4.6 — both around the mid-80s% on LCB. On math, Qwen might be slightly behind GLM (since even Alibaba’s numbers were a bit lower on AIME). And on creative writing or alignment, Qwen was known to be strong (as a continuation of their aligned chat models). Interestingly, when directly pitted, Kimi K2 beat Qwen’s coder version badly on real coding tasks, implying Qwen might have struggled with complex multi-step problems despite good benchmark scores. GLM-4.6, by contrast, has been stress-tested in those multi-step agent tasks and proven itself. So, while Qwen-3 Max is certainly one to watch (especially once Alibaba fully open-sources it), at this moment GLM-4.6 edges it out as the more battle-tested and integration-ready model for coding and agentic use.
In summary, GLM-4.6 emerges as arguably the best open-model all-rounder of late 2025. It may not categorically dominate every metric — Claude 4.5 is still superior in some niche areas like intricate debugging and extensive tool orchestration, and models like Kimi or DeepSeek have their specialized strengths — but GLM-4.6 is exceptionally strong across the board. It’s top-tier in coding, top-tier in math, very capable in knowledge and creative tasks, and it packages these abilities in an open, efficient form.
Independent Reactions and Real-World Feedback
Perhaps the most exciting aspect of GLM-4.6’s launch has been the community’s reaction. Developers and AI enthusiasts have been quick to put it through its paces, and many are singing its praises:
“Better Than Claude at Coding” — Several independent reviews describe GLM-4.6 as a breakthrough for coding tasks. One Medium tech author dubbed it “the best Coding LLM”, noting that GLM-4.6 “consistently beats GLM-4.5 across code tasks, matches Claude 4 in places, and is closing the gap with Claude 4.5”. This is significant because Claude 4.5 Sonnet was considered state-of-the-art in code generation. Early tests have GLM-4.6 producing code that often runs correctly on first try. Its ability to handle “fresh coding challenges” (new problems it hasn’t seen) and do so efficiently has been highlighted as a major strength.
Near-Frontier Performance at Fraction of Cost — A big theme in reactions is value. GLM-4.6 offers Claude-level performance for free or cheap. Zhipu’s pricing undercuts Anthropic by over 6x (just $0.60 per million input tokens vs $3.00 for Claude; $2.20 per million output vs $15 for Claude). There’s even a $3/month unlimited coding plan. This pricing democratizes access to high-end AI. As one reviewer put it, “This 6.2x cost difference makes GLM-4.6 highly accessible to organizations previously priced out of frontier AI”. Companies that balked at paying enterprise rates for closed models can now experiment freely with GLM. And beyond cost — the open-source license means no vendor lock-in and full customizability. Developers are excited to fine-tune GLM-4.6 on their data, something impossible with closed models. “It’s our model to tinker with,” one user remarked, emphasizing the empowerment that open weights bring.
“A Coding Monster That’s Free” — Many are struck by GLM-4.6’s combination of power and openness. On social media and forums, you see comments like “I have ChatGPT, Claude, and GLM 4.6, and I find myself going to GLM more”. Users mention that ChatGPT (GPT-4) has become overly cautious and refusals are common, whereas GLM will just solve the task as asked. Claude is creative but sometimes “goes off the rails” or isn’t as eager to produce code. GLM-4.6, on the other hand, feels like a happy medium — it’s creative yet stays on task, and doesn’t come with heavy usage restrictions. This has made it popular in the developer community; on the Local LLM arenas, GLM-4.6 quickly shot to the top rankings. In fact, GLM-4.6 became the #1 ranked open model overall on the LMArena benchmark (which reflects aggregate user preferences) shortly after release. It was noted as being particularly strong in “hard prompts” and “creative writing”, indicating general versatility, not just coding. Users appreciate that GLM-4.6 can be both an efficient coding assistant by day and a creative storyteller or helpful chatbot by night.
Critiques and Caveats — No model is perfect, and experienced users have pointed out a few weaknesses of GLM-4.6. First, Claude 4.5 still has the upper hand in complex, long-horizon autonomy. For example, Anthropic has demonstrated Claude achieving 30+ hour continuous sessions with persistent memory — something GLM hasn’t yet matched. In benchmarks like the weighted τ² agent test (mix of tasks), GLM lagged behind Claude (75.9% vs 88.1%). Similarly, for computer control (like operating a browser or desktop apps), GLM-4.6 has only rudimentary ability, whereas Claude 4.5 is leading with things like Chrome integration. Zhipu didn’t prioritize those features for GLM-4.6, focusing more on coding and text. So if a user’s goal is an AI that can, say, navigate a GUI or do complex multi-app workflows autonomously, Claude might still be the better pick today. Another noted gap is extreme real-time speed: GLM-4.6 is faster than its predecessor (token throughput ~50–100 tokens/sec via optimized servers, quite good for its size), but it’s not a “fast” model by smaller model standards. xAI’s new Grok Code Fast model, for instance, sacrifices a bit of peak accuracy to run lightning-quick (and indeed scored a similar ~70% on SWE but at 1/3rd the latency of others). In situations where response speed matters more than maximum quality (e.g. rapid code autocomplete), some developers might still opt for a smaller or specifically speed-tuned model over GLM. Lastly, ecosystem maturity: as one analysis noted, “Claude and OpenAI still have stronger third-party integrations and adoption outside China”. While GLM is catching up fast, tools like VSCode plugins, cloud platforms, etc., often integrated OpenAI or Anthropic first. This is changing (GLM-4.6 is now supported in many open-source agent frameworks and via OpenRouter API), but there is a bit of catch-up in community tooling.
On the whole, the reception of GLM-4.6 has been overwhelmingly positive. It’s not often that we see an open model so quickly crowned as a viable alternative to the best closed models. The consensus among early users and researchers is that GLM-4.6 marks a tipping point — the moment when open-source AI truly narrowed the gap to proprietary AI at the cutting edge. It offers a potent blend of performance, openness, and cost-efficiency that is hard to ignore.
GLM-4.6 continues a shift towards accessible excellence in AI. Developers now have, at their fingertips, a model that can code nearly as well as the top private models, reason through difficult problems, handle enormous context, and integrate tools – all while being open and affordable. This puts enormous power in the hands of startups, indie developers, researchers, and even hobbyists, who can build with a frontier-caliber model without begging for API access or blowing the budget.
From a broader perspective, GLM-4.6’s emergence underscores the healthy competition driving the field. Each competitor pushed it in different ways: Kimi’s MoE scale, DeepSeek’s reasoning depth, GPT-OSS’s efficiency, Qwen’s knowledge – GLM-4.6 managed to synthesize strengths from all, without the usual trade-offs. It embodies a pragmatic design philosophy: maximize real-world impact (coding agents, useful answers) rather than just leaderboard scores. Zhipu’s team even stated “real-world experience matters more than leaderboards” and backed it by releasing the Docker-based CC-Bench data for the community. This focus on practical utility is clearly resonating with users.
Learn more about GLM-4.6 Review. Zhipu AI’s GLM-4.6 is the latest leap…