Released on October 15, 2025, Claude Haiku 4.5 brings much of last spring’s flagship capability into a package that is dramatically faster and markedly cheaper to operate – enough to reshape how teams design AI systems for production workloads. At a high level, Haiku 4.5 is a pragmatic engineer’s tool: quick on the draw, and steady at multi-step software tasks.
Below, I break down what the model is, what it does well, how it behaves in practice, where it trails competitors, and why its launch matters for anyone building real products with AI today.
What Haiku 4.5 actually is
A small model with big-model affordances. Haiku 4.5 is Anthropic’s newest “fast tier” model, but it inherits capabilities that, until weeks ago, were reserved for the company’s larger Sonnet line. It supports a 200,000-token context window and up to 64,000 tokens of output, handles multimodal inputs (images + text), and, importantly for complex tasks , adds extended thinking and computer-use skills to the Haiku family for the first time. Extended thinking lets it allocate more deliberate computation before responding; computer use lets it act inside GUI/desktop/browser environments and is evaluated on real “operate the computer” benchmarks. It also adopts explicit context awareness, a training intervention that teaches the model to pace itself: wrap up when the context is nearly full, and keep reasoning when there’s headroom. This targets a common failure mode – agentic laziness – where models quit early or drop steps in long workflows.
A speed-and-cost play. On Anthropic’s platform, Haiku 4.5 is priced at $1 per million input tokens and $5 per million output tokens (with sizable discounts via prompt caching and batch APIs). In practice, teams are seeing 4–5× faster responses vs. Sonnet 4.5 on like-for-like tasks. Those two facts — lower unit cost and shorter wall-clock time — make it viable for real-time assistants, “sub-agent” workers, and high-throughput backends that would buckle under the latency or spend of heavier models.
Anthropic’s safest model (by its own tests). Haiku 4.5 ships under the ASL-2 safety level (fewer restrictions than ASL-3), with internal automated assessments showing a statistically significantly lower rate of misaligned behavior than Sonnet 4.5 and Opus 4.1. For teams operating in regulated environments, that matters: fewer blockages on legitimate requests, with the guardrails still catching obviously harmful instructions.
Benchmarks.

Benchmarks are not the whole story, but they remain the best public proxy for what a model can do. On release, Anthropic emphasized three areas: realistic agentic coding, terminal operations, and computer use.
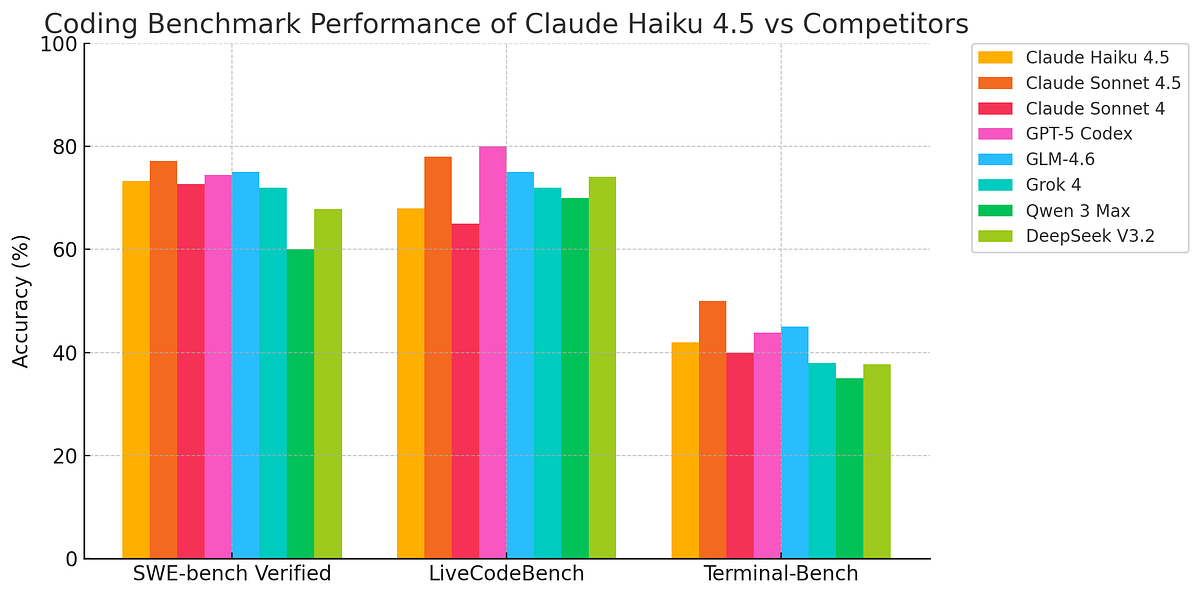
SWE-bench Verified (agentic coding on real GitHub repos). Haiku 4.5 posts 73.3% – a score averaged over 50 runs with a simple two-tool scaffold (bash, file-edit) and no test-time compute. That puts it within striking distance of the very top and, critically, on par with Anthropic’s own Sonnet 4 from earlier this year, at a fraction of the cost and markedly lower latency. The company’s framing – “what was recently frontier is now fast and cheap”- isn’t just marketing puff; the number backs it.
OSWorld (computer use in real applications). Haiku 4.5 lands at 50.7%, a notable jump over earlier Claude generations and a strong showing for a “small” tier model. This matters beyond the leaderboard: in practice, it correlates with whether an assistant can click through web apps, wrangle spreadsheets, or complete multi-step desktop tasks without falling apart.
Terminal-Bench (agentic Linux workflows). Using Anthropic’s Terminus-2 agent with default settings, Haiku 4.5 averages ~40–42% across 11 runs (slightly higher with modest thinking budgets), a tough benchmark where even frontier models barely cross the “half the tasks” line. It underscores a broader truth: terminal automation is still hard for everyone, but Haiku is competitive enough to be useful when wrapped in robust retry and check-steps.
Outside that “home turf,” Haiku’s performance is more mixed. Vals AI’s independent evaluation places Haiku 4.5 (Thinking) third overall on the Vals Index, with particular strength in coding/agentic tasks and middling results on some academic reasoning and domain-knowledge sets like GPQA, MMLU-Pro, MMMU, and LiveCodeBench. If you’re optimizing for the fastest high-quality coding assistant rather than acing graduate-level science quizzes, that trade-off is often acceptable.
How it stacks up: Claude’s rivals in late 2025
The 2025 field is dense and noisy, with every vendor publishing glowing charts. A sober comparative take looks like this:
Claude Sonnet 4.5 remains Anthropic’s frontier model – best-in-class on agentic coding and computer use – and still the pick for the hardest, most open-ended reasoning. Haiku 4.5’s job is not to replace it but to cover 70–90% of daily workloads at far better speed and cost. Many teams now design “barbell” stacks: route most traffic to Haiku; escalate the truly gnarly cases to Sonnet.
OpenAI’s GPT-5 family continues to set the tone on some reasoning-heavy and knowledge-dense benchmarks and is highly competitive on agentic coding, depending on variant and tooling. Anthropic’s own materials cross-reference OpenAI’s published results for SWE-bench and Terminal-Bench; in practice, most users evaluate GPT-5 vs. Claude on latency, price, and tool-use reliability for their pipeline rather than single-number deltas.
Alibaba’s Qwen 3 Max is the most interesting foil among non-US stacks. Alibaba claims 69.6% on SWE-bench Verified for the Max-Instruct variant – respectable, near-frontier performance for closed-source China-based models. Independent aggregators report lower numbers in some configs (e.g., ~62% on Vals), highlighting how scaffolding and “thinking” settings swing results. Takeaway: Qwen 3 Max is viable for coding, but variance across harnesses is real.
DeepSeek V3.2-Exp made headlines for slashing API prices while switching to sparse attention. It mostly matches V3.1-Terminus on quality, clocking ~67.8% on SWE-bench Verified and ~37.7% on Terminal-Bench in multiple provider dashboards. As open or semi-open ecosystems go, DeepSeek is the one to watch – strong coding value and aggressive costs – though many Western enterprises still weigh policy and procurement risks.
Zhipu’s GLM-4.6 pushes a gigantic sparse-MoE stack with 200K context and heavy tool-use emphasis, positioning it as a peer to Claude on long-context workflows. Official materials stress parity with prior Claude generations across broad leaderboards; fine-grained public numbers on SWE-bench vary by run and are sparser than Anthropic’s disclosures. For teams focused on China-market deployment, GLM remains a flagship option.
xAI’s Grok 4 (and “Heavy” parallelized modes) stands out for aggressive “always-on reasoning” and multi-agent execution. It has posted strong results on several reasoning sets and competitive agentic behavior; empirical SWE-bench numbers vary by harness and are less consistently reported than Anthropic/OpenAI. The product’s tone and alignment profile also differ — part strategy, part brand.
The meta-story across all of these: capability diffusion. Features once locked to the top SKU are now trickling down a tier or two within weeks. In that environment, buyers optimize for total cost of ownership: unit price × latency × reliability × orchestration fit. Haiku 4.5 is built to win that specific equation for a broad swath of production workloads.
Early reception from the trenches
GitHub Copilot’s team publicly praised its “comparable quality to Sonnet 4 but at faster speed,” exactly the profile you want from an on-type-ahead coding assistant. Anthropic’s own Claude for Chrome feels appreciably quicker in day-to-day browsing and automation, and the model is now the default on Claude.ai for free users, which exposes it to a massive base immediately. AWS (Bedrock) and Google Cloud (Vertex AI) added it to their catalogs on day one.
Developers’ qualitative feedback is surprisingly consistent:
- Speed that changes behavior. Teams report that the reduction in round-trip time collapses iteration loops: refactor → test → adjust feels like continuous motion rather than lurch-and-wait. That effect compounds in multi-agent setups (more on that below). Media coverage singled out Haiku’s “do things fast” personality as a virtue, not a gimmick.
- Surgical on scoped code edits; more average on open-ended creativity. If you hand Haiku 4.5 a repository task with clear tests and constraints, it tends to make tight, localized edits that pass. Ask for a novel algorithmic approach or a flash of creative code design and larger models still feel steadier. Independent benchmark aggregators echo this: strong in agentic coding and terminals, middle-of-pack on LiveCodeBench and academic reasoning.
- “Junior engineer” verbosity crops up. Some early testers complain about over-engineering or verbose scaffolding on loosely specified tasks. That’s not unique to Haiku — but because the model is fast and affordable, teams are more willing to iterate prompts and guardrails to tame it. The upside: verbosity is easier to refactor than silence. The downside: you need style guides and linting in the loop. (This is where an orchestrator model enforcing “hard rules” helps.)
- A smoother path through safety. Enterprises sensitive to governance concerns like that Haiku carries ASL-2 rather than the stricter ASL-3 classification of bigger Claude models. In practice, that often means fewer false positives on allowed tasks without opening the door to obviously disallowed content.
- None of this says Haiku 4.5 is perfect. It will still stall on very long terminal sequences, occasionally mis-click GUIs, or produce boilerplate where you wanted elegance. But when paired with explicit checks (tests, schema validators, simple “critique then fix” loops), it’s robust enough to ship.
Where Haiku 4.5 fits in your stack
The most effective production pattern I’ve seen shake out this year is a tiered orchestration:
- Route by difficulty and risk. Default to Haiku 4.5 for the bulk of requests — especially latency-sensitive chat, scoped code edits, doc synthesis, data extraction, and tool-centric workflows. Add simple shape constraints (output schemas), budgeted thinking, and auto-tests to keep it tight.
- Escalate hard cases. For ambiguous, high-stakes, or “design a novel approach” tasks, escalate to Sonnet 4.5 (or an equivalent heavy model). Let the heavy model decide whether to proceed alone or to decompose the work and delegate back to a swarm of Haiku workers.
- Run it as a multi-agent system. The orchestration loop becomes: Plan (heavy) → Execute (many Haiku) → Verify (tests/linters) → Review (heavy). Anthropic itself recommends and demonstrates this pattern, and cloud vendors now surface Haiku across products (Claude Code, Bedrock, Vertex) to make it convenient. It maps cleanly to how engineering teams already work: architects decide; implementers build; CI verifies.
- Exploit the economics. With $1/$5 per million tokens and bulk discounts via prompt caching and message batches, you can afford to parallelize Haiku for throughput while keeping the expensive planner hot only when needed. This is why the “barbell” strategy is suddenly mainstream rather than an academic diagram.
A note on pricing optics
There’s been spirited discussion about whether Haiku 4.5 is “cheap enough” relative to mini models from other labs. It is not a race-to-the-bottom SKU like the tiniest nano/flash variants from OpenAI or Google; it’s priced like a premium small model because it delivers premium small capability on agentic work. If you’re bulk-generating boilerplate or stuffing commodity summaries into a cache, a rock-bottom mini may still pencil out. But for live coding, customer support with tool use, and orchestration where accuracy and speed interact, Haiku’s total cost to solution tends to be lower — fewer retries, fewer stalls, fewer handoffs. Independent practitioners analyzing prices in the round have made exactly that point this week.
What the three supplied articles got right — and where the internet disagrees
Across the three texts you provided, the core shape is correct: Haiku 4.5 collapses the speed–quality trade-off for a wide slice of work; it inherits extended thinking and computer use; it scores 73.3% on SWE-bench Verified; and it’s positioned to be the fast worker in a manager/worker setup where Sonnet 4.5 orchestrates. Those claims are all substantiated by Anthropic’s product page and launch post.
Where detail diverges, public sources clarify the picture:
- Terminal-Bench: Treat exact numbers with care. Anthropic reports ~40–41.75% for Haiku 4.5 under Terminus-2 across 11 runs with default settings — and specifies run budgets. That sits below Sonnet 4.5 and roughly in line with strong non-frontier models. Assertions that Haiku is “around 42–45%” are broadly accurate but depend heavily on harness and n-attempts.
- Vals AI ranking: Vals reports Haiku 4.5 (Thinking) at #3 on its composite index yet also notes middle-tier results on several academic sets and LiveCodeBench. The nuance matters: Vals likes Haiku on the real-world stuff; it’s just not the best model at everything.
- Qwen 3 Max on SWE-bench: Alibaba’s 69.6% claim appears in official blogs and press, but independent dashboards show lower figures in some settings (≈62%) — likely reflecting differences in tool use and chain-of-thought budgets. If you evaluate Qwen for coding, replicate the harness before assuming parity.
- DeepSeek V3.2-Exp: Multiple third-party providers converge on ~67.8% SWE-bench Verified and ~37.7% Terminal-Bench — basically equal to V3.1 with big cost cuts. If you prefer open-ish stacks and low pricing, that’s credible value, just shy of the closed frontier trio on agentic coding.
- Taking all that together: the web largely agrees with the thrust of the articles, with a few numbers tightened and a few claims tempered.
Bottom line
Claude Haiku 4.5 is a workhorse tuned for the jobs most teams actually run – chat with tools, code with tests, search-and-patch across big repos, click through structured UI tasks – at a pace that keeps humans in flow. It does not dethrone the largest models on the most abstruse reasoning sets, nor does it magically solve the last 10% of brittle terminal automation. But it materially shifts the cost and latency profile of useful AI.
If you’re already in the Claude ecosystem – Claude Code, Claude for Chrome, Bedrock, Vertex – you get an immediate upgrade path. If you aren’t, Haiku 4.5 is the most compelling “small-but-serious” model to pilot for real-time agentic use this quarter. The rest of the industry will answer in kind, because the new frontier isn’t just raw IQ. It’s IQ × speed × price × fit.
Learn more about Claude Haiku 4.5 Review. Released on October 15, 2025, Claude…