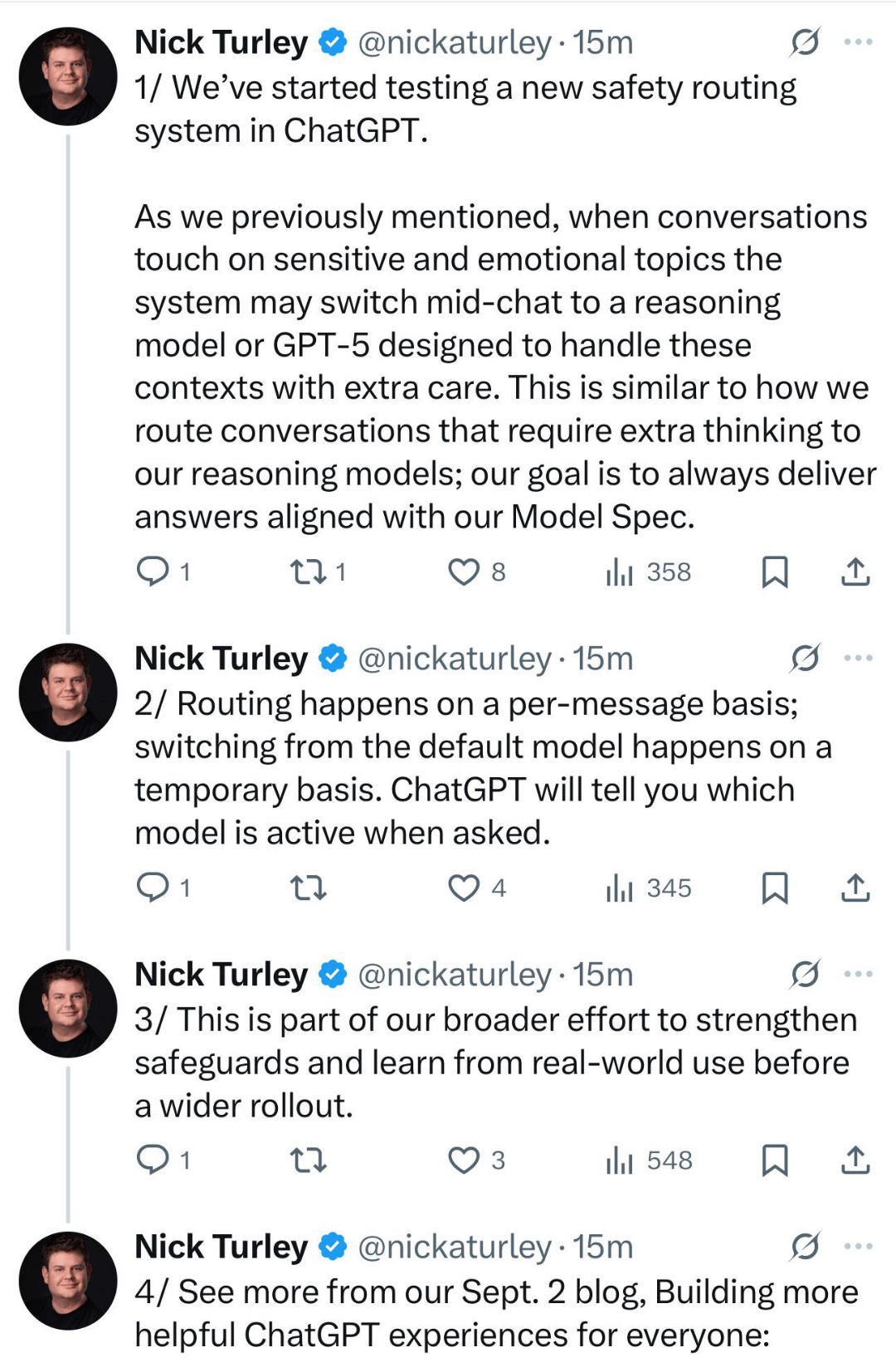

I am unsure whether we actually see the "thinking for a better answer" message before receiving a response when the 5 basic gets rerouted or whether the thinking of the safety model happens internally without our awareness and then the answer is simply sent as if it came from 5 basic. I am honestly unsure if I've seen this happening but my statistics do show that the model has been interacted with.
I'm thinking we wouldn't have a way to distinguish between GPT-5 thinking and GPT-5 chat safety if the interface doesn't differentiates them or if we don't get to see the reasoning being triggered but only the final answer.
I'm thinking we wouldn't have a way to distinguish between GPT-5 thinking and GPT-5 chat safety if the interface doesn't differentiates them or if we don't get to see the reasoning being triggered but only the final answer.
You can see the % of the models you've interacted with by asking GPT to show you the User Interaction Metadata. Memory needs to be on.