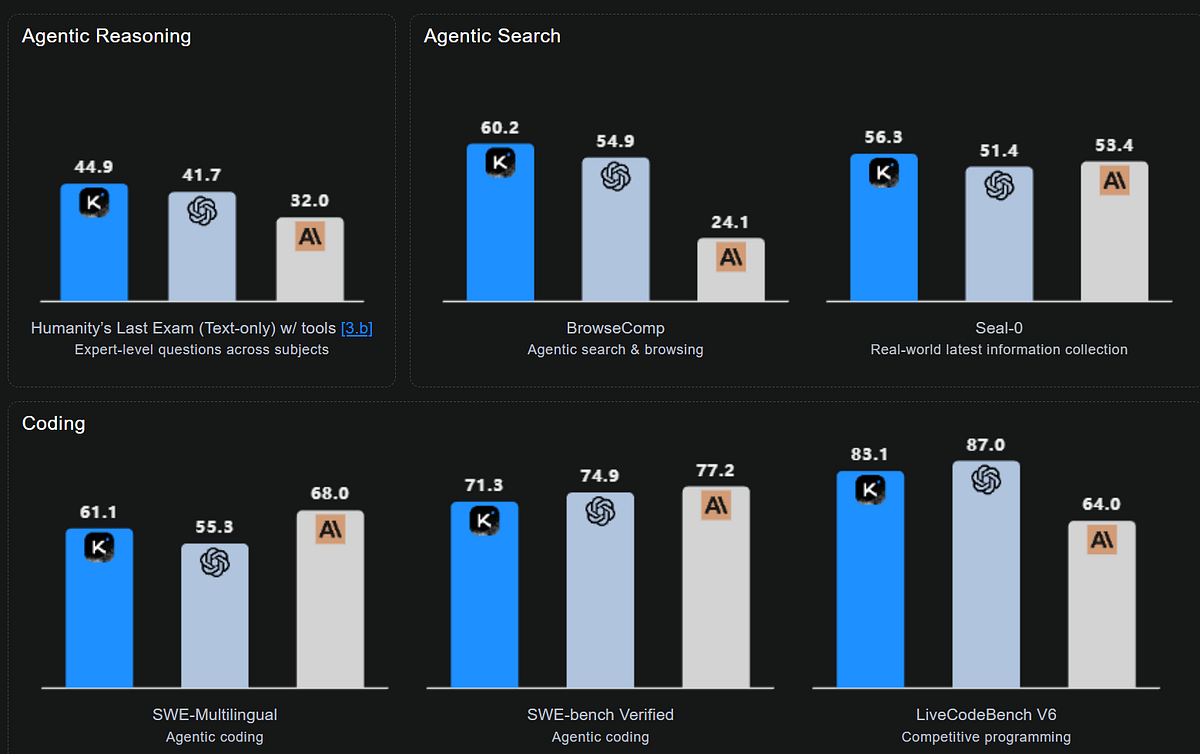
Moonshot AI’s Kimi K2 Thinking is a new open-source AI model that was just released (November 11th, 2025). Released in early November, this model packs a 1 trillion parameters and is designed as a “thinking” agent – meaning it doesn’t just answer questions, but can reason step-by-step and use tools to solve complex tasks. In initial evaluations it has set state-of-the-art scores on challenging benchmarks like Humanity’s Last Exam (HLE) and BrowseComp, in some cases even outperforming closed models from industry leaders. Perhaps most impressively, K2 Thinking excels at programming tasks: it’s one of the best code-generating AIs ever open-sourced, narrowing the performance gap between open models and proprietary systems to the smallest it’s ever been.
Inside the K2 Thinking Model
What makes Kimi K2 Thinking so special? Under the hood, this model is a Mixture-of-Experts (MoE) transformer with 1 trillion total parameters (32 billion active). In simple terms, it’s like an ensemble of many expert subnetworks that together can tackle a wide range of problems efficiently. It also boasts an unprecedented 256,000-token context window, allowing it to read and “remember” hundreds of pages of text in one go — useful for lengthy coding sessions or deep research problems. Uniquely, K2 Thinking has been trained to think aloud: it generates intermediate reasoning steps and can dynamically call tools (like search engines, calculators, or code interpreters) within its responses. In fact, it can string together 200–300 tool calls in sequence without losing track — a capability previously seen only in a few bleeding-edge proprietary models. To keep this enormous “brain” usable, Moonshot AI employed Quantization-Aware Training to compress the model to native 4-bit weights, drastically reducing memory usage and doubling inference speed with minimal loss in accuracy. All these features combine to make K2 Thinking a robust, agentic AI: it can plan, reason, and take actions (via tools) over very long dialogues or problem-solving sessions.
Key features of Kimi K2 Thinking include:
a) Deep Reasoning & Tool Use: Trained to intermix chain-of-thought reasoning with API calls, enabling autonomous multi-step workflows (research, coding, writing) that can span hundreds of coherent steps.
b) Massive Scale MoE Architecture: A trillion-parameter network with 384 expert modules (32B parameters active per token) – giving it both breadth of knowledge and specialization. This architecture helped it achieve record results on benchmarks like HLE and BrowseComp that require combining knowledge with reasoning.
c) Long-Horizon Memory: A 256K token context (roughly 200+ pages of text) so it can handle extensive codebases or lengthy documents. Long-context tasks that stump ordinary models are within K2’s grasp, as seen in its high scores on long-form evaluations and web browsing challenges.
d) INT4 Quantization for Speed: Through 4-bit quantization, K2 runs significantly faster and leaner at inference time. Notably, all its published benchmark results were achieved in this 4-bit mode – demonstrating top performance as it would actually be deployed, not just in ideal conditions.
These design choices make K2 Thinking not only powerful in theory, but practical to use (at least on enterprise hardware). “It’s awesome that their benchmark comparisons are run the way it’ll be served. That’s the fair way,” noted one AI analyst, referring to K2’s INT4-serving strategy. The model’s capabilities aren’t purely academic: early users have remarked that K2’s writing quality and “voice” remain strong even through lengthy reasoning chains. In other words, it doesn’t devolve into incoherence over hundreds of steps – it stays on point and preserves a consistent style. This combination of deep reasoning with polished output gives K2 Thinking a distinctive edge for real-world applications.
Mastering Coding Tasks
One domain where Kimi K2 Thinking truly shines is coding. Moonshot AI put a special emphasis on programming abilities during K2’s training, and it shows. In evaluations, K2 Thinking has emerged as the top open-source model for code generation and software engineering assistance. For example, on a challenging software benchmark involving resolving real GitHub issues, K2 solved roughly 69% of the tasks correctly. By comparison, OpenAI’s latest GPT-5 (with its own “thinking mode” enabled) is only a bit higher at ~75% on the same test, and Anthropic’s Claude 4.1 is around 74.5%. This means K2 Thinking has essentially caught up to within a few points of the best closed models in coding – a remarkable feat for an open model. It handily beats other open competitors on code: an earlier version of DeepSeek’s model managed ~58% on that benchmark, far behind K2’s score. Another rival, Qwen (Alibaba’s model), was tested on a set of large-scale coding challenges where it solved only 47% of problems, while K2 solved a whopping 93%. That kind of gap underscores just how consistent and reliable Kimi has become at programming tasks.
Diving into specific coding benchmarks, the story is the same. In an official LiveCodeBench test (which measures writing correct code for given tasks), K2 Thinking achieved about 83% accuracy, significantly ahead of DeepSeek-V3.2’s ~74%. It also outperformed DeepSeek on algorithmic coding challenges like OJ-Bench (C++ programming problems) and terminal automation tasks. In one terminal-oriented benchmark, K2 scored ~47.1 while DeepSeek’s model trailed at 37.7 – K2 found more correct solutions using its tool-calling capabilities. These results reflect Moonshot’s laser-focus on coding: they fine-tuned K2 on extensive programming data and even taught it to use a “bash shell” tool for executing code internally during its reasoning. The payoff is that K2 can not only write code, but also debug and refine it autonomously over many steps.
Equally important is how K2 approaches coding problems. Thanks to the huge context window, it can ingest very large codebases or documentation and maintain awareness of all those details while coding. And with its chain-of-thought ability, it often plans out a solution stepwise — describing its approach, calling a Python interpreter tool to test snippets, adjusting code if needed, and so on. This resembles how a human software engineer might work through a problem, and it leads to impressive results on complex tasks that require iterative thinking. Developers who have tried K2 Thinking in coding scenarios report that it sticks to requirements diligently and produces well-structured, commented code. It’s also multilingual in code: benchmarks included tasks in languages from Python to C++ and K2 handled both algorithmic logic and UI/front-end code generation with aplomb. All told, Kimi K2 Thinking has set a new high-water mark for open AI in programming, reducing the need to rely on closed-source coding assistants.

Head-to-Head with Other Frontier Models
The emergence of K2 Thinking comes amid a broader race in AI: a handful of cutting-edge models are vying for the top spot in reasoning, coding, and “agentic” abilities. How does Kimi K2 compare with its nearest peers? Below we examine K2 alongside three other prominent large models of 2025:
- DeepSeek-V3.2-Exp (DeepSeek AI): DeepSeek is another leading lab that open-sources its models, and K2 Thinking’s closest cousin in many ways. DeepSeek’s earlier R1 model (released mid-2025) was one of the first open AIs explicitly trained for step-by-step reasoning, and it famously rivaled OpenAI’s own models in math, logic, and coding tasks. The new DeepSeek-V3.2-Exp is a hybrid model built on a similar Mixture-of-Experts base (around 671B parameters, 37B active) with a 128K context window. Its standout innovation is DeepSeek Sparse Attention (DSA) — a technique to selectively focus the model’s attention in long contexts, which dramatically improves efficiency. Thanks to DSA, V3.2-Exp can handle long inputs faster and cheaper; DeepSeek even slashed their API prices by over 50% upon its release, highlighting the efficiency gains. In terms of raw performance, V3.2 is reported to be on par with the previous V3.1-Terminus model — meaning it remains a very strong general-purpose AI. It especially excels at complex reasoning and math: DeepSeek’s team has a core strength in training models to generate rigorous chain-of-thought (their R1 was peer-reviewed and known for “thinking” out loud logically). Indeed, on pure math competitions like AIME or algorithmic puzzles, DeepSeek models still slightly outperform Kimi K2 in accuracy. However, when it comes to coding and tool-based problem solving, K2 Thinking now has the upper hand. Moonshot’s extra fine-tuning on code and tool use means K2 often scores higher on programming benchmarks than DeepSeek V3.2. For example, as noted earlier, K2 leads by several points on coding challenges that both have been tested on. The two are in a bit of a friendly rivalry: Kimi K2 can be seen as the new champion of coding and long-form multi-step tasks, whereas DeepSeek models remain slightly better at disciplined logical reasoning in certain domains (and are very fast, thanks to DSA). Both being open-source is a boon for the community — they’re pushing each other and rapidly closing whatever gaps remain with the proprietary giants.
- GLM-4.6 (Zhipu AI): Another major player is GLM-4.6, the latest in the GLM series from Zhipu AI (also known as Z.AI, a Tsinghua University spinoff). GLM-4.6 is a 357 billion–parameter MoE model with a 200K context window. Notably, Zhipu built this model using domestic hardware and released it under an open license, proving that it’s possible to achieve frontier-level AI without NVIDIA GPUs and at a fraction of the typical cost. In fact, GLM-4.6 has been offered via a low-cost subscription (on Zhipu’s API) that undercuts Western models’ pricing by up to 50× — a bold move that has rapidly drawn in developers. Within days of launch, GLM-4.6 shot to #4 on global LLM leaderboards and became the highest-ranked open model. Performance-wise, it is very much in the same league as K2 Thinking. GLM was built to unify skills in coding, reasoning, and tool use, making it a strong “agentic AI” similar in spirit to K2. On many benchmarks GLM-4.6 is comparable to Anthropic’s Claude 4.5 (Sonnet) — for instance, Zhipu reported that GLM reached Claude’s level on a battery of eight authoritative exams ranging from math (AIME) to web browsing (BrowseComp). Its coding ability is especially touted: in a set of real-world coding tests run in the Claude Code environment, GLM-4.6 actually outperformed Claude’s model, winning ~48.6% of head-to-head coding challenges against Claude 4. This led many users to bring GLM-4.6 into their development workflows. Anecdotally, programmers describe GLM-4.6 as “snappy and reliable” — it produces solutions quickly and rarely goes off-track. One Reddit user even noted that GLM-4.6 felt “almost as good as Anthropic’s Sonnet 4.5 and probably better than GPT-5” for his complex tool-using agent tasks. Another developer recounted how GLM-4.6, via an IDE plugin, refactored a large React codebase effortlessly, calling it and Claude Code “beasts” of coding assistance. In daily use, GLM’s advantages are its speed and cost-effectiveness — it delivers perhaps 80–90% of the top-tier AI capability at about 2% of the price, as one analysis put it. That said, GLM-4.6 isn’t entirely flawless. It can occasionally lag behind the absolute best models on the very hardest tasks; for example, it might require a couple more hints than GPT-5 to solve a tricky puzzle, or produce slightly more syntax errors in generated code under pressure. But these differences are fairly minor, and the consensus is that GLM-4.6 has effectively “democratized” high-end AI. For Kimi K2, GLM is both a competitor and a kindred spirit — another demonstration that open(ish) models can reach the top. It wouldn’t be an exaggeration to say GLM-4.6 and Kimi K2 Thinking collectively put serious pressure on the closed models’ dominance, by showing how fast the open alternatives are catching up.
- Qwen-3-Max (Alibaba Cloud): Qwen-3-Max is the wildcard in this comparison, as it’s the one model here that isn’t open source — but it’s too important to ignore. Developed by Alibaba, Qwen-3-Max is a trillion-parameter model like Kimi K2 (actually the largest in Alibaba’s Qwen series) and was introduced in preview form in September 2025. Being a closed model accessible via API, Qwen3-Max nonetheless made waves with its performance: it ranked third on the TextArena leaderboard upon release, even surpassing OpenAI’s GPT-5 Chat at the time. In Alibaba’s internal evaluations, Qwen-3-Max achieved state-of-the-art results across a broad spectrum — from knowledge QA and multi-lingual understanding to reasoning, instruction following, and coding. In other words, it’s a very balanced, generalist AI with no obvious weak spots. Where Qwen really stands out, though, is enterprise-scale tasks — it was built with business applications in mind. It features a 262K context window (only slightly behind K2’s 256K) and has an innovative “context caching” system to reuse computations on long conversations. The result is that Qwen-3-Max can handle extremely long documents or dialogues quickly, making it suited for tasks like analyzing company reports or powering chatbots that remember entire chat histories. On coding benchmarks, Qwen-3-Max is reported to be excellent as well. It was integrated as the default AI assistant in Alibaba’s popular coding tool “AnyCoder”, indicating Alibaba’s confidence in its coding reliability. Early tests showed Qwen slightly outperforming open models like Kimi and DeepSeek on some coding tasks; for instance, on LiveCodeBench, Qwen-3-Max produced correct code more often than K2 in Alibaba’s comparison. Its prowess ranges from creating complex applications (one tester got Qwen to generate an entire voxel 3D game scene from a single prompt) to understanding nuanced coding instructions such as partial code edits. That said, until very recently Kimi K2 had an edge in code-specific fine-tuning — Moonshot’s model was beating Qwen’s previous versions in consistency and adherence to requirements for large coding projects. But Alibaba is not standing still: they have announced a forthcoming “Qwen3-Max-Thinking” variant, which is essentially Qwen with chain-of-thought and tool use similar to K2. In fact, this thinking version (still in training as of Nov ’25) has already hit 100% accuracy on notoriously hard math benchmarks (AIME, HMMT) when it’s allowed to use tools and extra computation. That foreshadows a model that could directly challenge K2 Thinking on its home turf of autonomous multi-step reasoning. For now, Kimi K2 and Qwen3-Max can be seen as parallel super-giants: one open-source, one closed; one perhaps a tad better at coding, the other with slightly more raw power in certain domains. Both are at the very cutting edge. And notably, both coming from Chinese companies — underscoring the rapid rise of China’s AI labs on the global stage.
Challenges and Impact
The debut of Kimi K2 Thinking signals a pivotal moment in the AI landscape. For one, it narrows the gap between open and closed models to almost nil on many frontiers. Not long ago, the best open-source language models lagged significantly behind systems like GPT-4. Now we have an open model nearly matching the rumored GPT-5 on key tasks, and even beating it on some tool-augmented challenges. This is forcing the closed labs (OpenAI, Anthropic, etc.) to take notice. When independent evaluations show a freely available model like K2 outscoring a top-tier proprietary model on a hard exam, it upends the notion that only the tech giants can build the most advanced AI. There’s a clear pressure on closed-model providers to justify their premium offerings, whether through greater reliability, safety, or integration, because purely in terms of raw capability the playing field is leveling.
It’s also worth noting how quickly this progress is happening. Kimi K2 came just months after DeepSeek’s and Zhipu’s major releases, which themselves were only a few months behind the latest from OpenAI/Anthropic. Labs in China, in particular, have shown an ability to iterate extremely fast — sometimes releasing multiple frontier models in the span of weeks. This rapid cadence (“move fast and share things”) has led to a virtuous cycle in the open AI community. Each new model — be it DeepSeek’s reasoning expert or Zhipu’s coding wizard or Moonshot’s all-rounder — pushes the envelope further and provides new building blocks for others. Users now have an embarrassment of riches: if one needs a strong reasoning assistant, there’s DeepSeek R1; for a coding co-pilot, K2 Thinking or GLM-4.6 are available; if ultra-long context or bilingual support is crucial, Qwen-3-Max is there, etc. And these are not just trivial chatbots — they are frontier models in their own right. As one observer put it, “a growing share of cutting edge mindshare is shifting to China”, with multiple Chinese labs now in the top tier of AI development.
Of course, K2 Thinking’s open-source status comes with some caveats. The model weights are immense — over 600 GB even in 4-bit compression. Running this model at full capacity is beyond the reach of casual users (it demands clusters of high-memory GPUs or TPUs). This has led to community discussions about distilling or fine-tuning smaller versions of K2 that could run on more modest hardware, or using model compression techniques to make it more accessible. Moonshot might well release scaled-down variants (for example, a 32B or 64B model) that preserve some of the “thinking” prowess. Until then, most will interact with K2 via cloud platforms or public APIs. Despite that, having the weights open is crucial — it means researchers can inspect how the model works, and independent benchmarks can be run without restriction (indeed, many of K2’s benchmark wins have been verified by third parties). It’s a level of transparency that closed models don’t offer.
Initial user feedback on K2 Thinking has been very positive, albeit with some tongue-in-cheek commentary on its style. Like other large models, K2 can occasionally produce verbose or generic prose — what some AI enthusiasts jokingly call “AI slop.” Interestingly, a few users remarked that “GPT slop reads like a Medium post, whereas K2 slop reads like it was trained on LinkedIn posts.” In other words, K2’s writing might come off a bit more formal or business-like compared to GPT’s. While meant humorously, it highlights that each model has its own personality shaped by its training data. Moonshot might have leaned into technical and formal texts for K2’s training mix (or perhaps it’s an artifact of the reinforcement learning process). The good news is that such differences are mostly superficial — and could potentially be tuned. More importantly, on substance K2’s outputs have been described as highly factual and on-target, which matters far more for serious use. Any lingering “vibe” issues (as some call it) don’t diminish the fact that this model can solve problems no open model could handle before.
Another aspect generating buzz is how K2 Thinking maintains coherence over very long sessions. Users have pushed it to generate extremely lengthy answers, or to carry on multi-turn dialogues that span thousands of tokens, and found that it doesn’t forget details or go off on tangents easily. This is likely due to both the long context size and the model’s training for persistence in tool-augmented tasks. It’s a promising sign for applications like AI agents that need to carry out extended missions (e.g. writing complex software from scratch, step by step). K2 Thinking essentially served as a proof-of-concept for the AI community that “long-horizon agency” is achievable in an open model. Where earlier open agents would drift or break after maybe 30 steps, K2 showed you can sustain logical behavior for 10× as long. This raises the ceiling for what AI assistants might do autonomously — potentially enabling full project completion, sophisticated research tasks, and other “auto-GPT” style use cases that were previously unreliable.
Kimi K2 Thinking represents a milestone: it’s an open-source, trillion-parameter genius that in many ways matches the best AI systems in the world. For developers and researchers, it offers an unprecedented combination of abilities — world-class coding skills, deep reasoning with tool use, huge memory, and fast inference — all in a model they can actually inspect and build upon. The arrival of K2 Thinking and its contemporaries also marks the beginning of a new era of competition. No longer are cutting-edge AI models only in the hands of a few tech giants behind APIs; now there are multiple, globally distributed teams producing top-tier models and releasing them openly. This competition is already yielding faster innovation and more choice. If GPT-4 was the peak of a closed, proprietary mountain, models like Kimi K2 are charting a new route up that mountain’s face, one that is open for everyone to climb. And they are reaching astonishing heights – perhaps just a few steps shy of the summit that was, until recently, reserved for the likes of GPT-5.
The broader implication is that AI development is becoming a more democratized, collaborative endeavor. Kimi K2 Thinking’s success will spur others to push further (indeed, we’re already anticipating Qwen’s thinking model and DeepSeek’s next update). Users will benefit from better systems at lower cost, and researchers benefit from having high-performance models they can study without NDAs. It’s a virtuous cycle that accelerates progress. There are still challenges ahead, from managing the compute demands of these behemoths to ensuring they are used responsibly, but the trajectory is clear.
Learn more about Kimi K2 Thinking Review. Moonshot AI’s Kimi K2 Thinking is a new…