Launched on November 18, 2025 and immediately wired into the Gemini app, and a brand-new agentic IDE called Antigravity, Gemini 3 Pro is the centerpiece of a broader strategy: turn AI from a talking interface into the computational substrate of modern software.
This is not happening in a vacuum. OpenAI’s GPT-5.1 and Anthropic’s Claude Opus 4.1 arrived just days and weeks earlier.

Inside Gemini 3 Pro: A Trillion-Scale Multimodal Engine
At the hardware-mindset level, Gemini 3 Pro is built to be large and selective. Under the hood sits a trillion-scale sparse Mixture-of-Experts stack that only activates a subset of its experts per token, giving it enormous representational capacity without linearly exploding inference cost.
Two design decisions matter most:
1. One-Million-Token Context. Gemini 3 Pro can ingest around a million tokens of input — hundreds of thousands of words, or hours of transcript and logs — in a single shot, while generating up to 64k tokens of output. That’s enough to load a sizable codebase, an entire due-diligence data room, or multiple textbooks and reason across them without elaborate RAG gymnastics.
2. Native Multimodality. Unlike architectures that glue a separate vision encoder onto a text model, Gemini’s core transformer takes text, images, audio, video frames, and PDFs as first-class citizens. This pays off on benchmarks that require true cross-modal thinking — diagrams plus problem statements, UI screenshots plus instructions, slide decks plus narration.
On top of that sits a thinking_level control and a forthcoming Deep Think mode. thinking_level lets developers trade latency for depth on a per-request basis, while Deep Think — currently in limited safety testing — allocates extra inference-time compute to extremely hard problems, exploring multiple solution paths before responding. Early numbers show Deep Think nudging Humanity’s Last Exam and ARC-AGI-2 scores up several points beyond the already-high Pro configuration.
In short: Gemini 3 Pro isn’t just bigger. It’s structurally set up to be better at problems that require slow, deliberate reasoning across many modalities and many pages.
Benchmarks: Where Gemini 3 Actually Wins
The launch narrative around Gemini 3 Pro has been benchmark-heavy, and for once, the marketing bullet points mostly survive contact with the data.
General Intelligence and Academic Reasoning

On the new crop of “adversarial” benchmarks designed to trip up frontier models, Gemini 3 Pro pulls ahead:
• Humanity’s Last Exam (HLE): About 37–38% accuracy without tools, versus roughly the mid-20s for GPT-5.1 and low-teens for Anthropic’s latest Claude Sonnet tier.
• GPQA Diamond (graduate-level science): Around 92% for Gemini 3 Pro, ahead of GPT-5.1 in the high-80s and Anthropic’s best in the low-80s.
• MathArena Apex: A new “final boss” benchmark of Olympiad-style problems where most models barely register; Gemini 3 Pro lands at 23.4%, while GPT-5.1 and Claude hover around 1–2%.
These numbers don’t mean Gemini is suddenly a Fields Medalist. But they do indicate a meaningful jump in high-end reasoning — particularly in tasks that combine textual reasoning with intricate symbolic or visual structure.
It’s worth flagging that some of these benchmarks are controversial. Future House and others have pointed out that a sizable chunk of HLE’s biology and chemistry questions are simply wrong or poorly specified, raising questions about how much we should read into small percentage deltas. Still, even with some label noise, double-digit gaps between models are hard to ignore.
Multimodal and UI Understanding
Where Gemini 3 Pro’s architecture really flexes is in multimodal benchmarks:
• MMMU-Pro (broad multimodal understanding): Gemini 3 Pro hits roughly 81%, ahead of GPT-5.1 in the mid-70s and Claude’s top tier slightly above that.
• Video-MMMU: Around 87–88% for Gemini 3 Pro, reflecting strong comprehension of long-form video lectures and clips.
• ScreenSpot-Pro (UI understanding): The standout metric: Gemini 3 Pro scores 72.7%, while GPT-5.1 barely clears low single digits on the same test. Even specialized computer-use models trail it by a significant margin.
• That last number matters. ScreenSpot-Pro probes how well a model can read screenshots of real software — menus, dialogs, spreadsheets — and answer questions or choose actions. A model that can’t see the UI can’t reliably be a computer-using agent. Gemini 3 Pro’s leap here is why Google feels comfortable wiring it directly into Search’s new “AI Mode” and into Antigravity’s browser-driven workflows.
Coding: Parity on the Basics, Edge on the Hard Stuff
On the mainstream coding benchmarks, the big three are essentially tied:
• SWE-bench Verified: Gemini 3 Pro, GPT-5.1, and Claude Opus 4.1 all cluster in the mid-70s for pass@1 on real GitHub issues. Even a percentage point of difference is within noise.
Where Gemini 3 Pro pulls away is in agentic and adversarial coding:
• LiveCodeBench / Codeforces-style Elo: Gemini 3 Pro posts an Elo around 2439, versus roughly 2240 for GPT-5.1 and much lower for Claude on contest-style problems.
• Terminal-Bench 2.0 (coding with a shell): Gemini lands in the mid-50s, ahead of GPT-5.1 in the high-40s and Claude in the low-40s, indicating stronger competence as a command-line agent rather than just a code generator.
• Vending-Bench and other long-horizon agent tests: On simulated environments where an agent has to plan and execute dozens of actions to maximize return, Gemini 3 Pro significantly out-earns GPT-5.1 and Anthropic’s latest, hinting at more stable long-term planning.
Put bluntly: if you just want bug fixes and docstrings, any of the three will do. If you want an AI that spins up a full stack app, scaffolds the infra, and iterates on it inside a shell or browser, Gemini 3 starts to look like the sharper tool.

Leaderboards and Meta-Scores
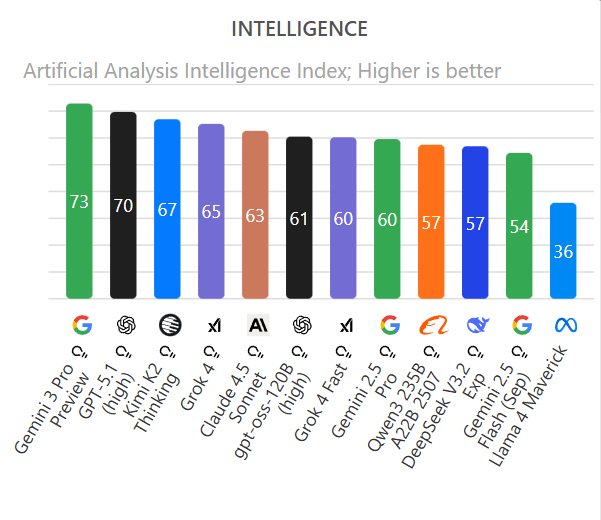
Perhaps the most visible badge: Gemini 3 Pro now sits at the top of the LMSYS Chatbot Arena Elo table with a score around 1501, edging out Grok 4.1 and the previous Gemini 2.5 Pro. It also leads the Artificial Analysis “Intelligence Index” across roughly half of the included evaluations.
That doesn’t make it “AGI” – but it does validate Google’s claim that, on paper, Gemini 3 Pro is currently the most capable general-purpose model in public testing.
Vibe Coding, Deep Think, and the Antigravity Gambit
One of the most striking differences between Gemini 3 Pro and its rivals isn’t just the model; it’s how Google wants you to use it.
Vibe Coding and Generative UI
Google is leaning hard into the idea that “natural language is the new syntax.” In AI Studio and Antigravity, you can sketch a UI, describe a “vibe” (“futuristic nebula dashboard in dark mode”), and Gemini will generate a working front-end with responsive HTML/CSS/JS, sometimes even hooking in real APIs. WebDev Arena scores back this up: Gemini 3 Pro currently tops that leaderboard, reflecting unusually strong performance on end-to-end web dev prompts.
That same engine powers Google’s “Generative UI” experiments in Search and Gemini Labs, where instead of a static snippet, the model produces interactive graphs, simulations, or decision tools on the fly. If a physics student asks about the three-body problem, Gemini can answer with a live orbital simulation instead of a wall of text.
This is more than UX sugar. It’s a direct challenge to the web’s business model: if the answer is a bespoke interface generated inside Search, users never need to click out to a third-party site.
Antigravity: The Agentic IDE
To fully exploit Gemini 3’s agentic coding, Google shipped Antigravity, a free, cross-platform agent-first IDE. Here, Gemini 3 Pro isn’t just autocompleting lines — it’s a first-class actor in the workspace. Agents get direct access to:
• An editor view that looks like a conventional IDE.
• A terminal pane for running tests, migrations, and scripts.
• An embedded browser for validating changes and driving UI tests.
Crucially, Antigravity generates “Artifacts” — task lists, plans, screenshots, and recordings that document what the agents did, giving developers something more interpretable than a stream of JSON tool calls.
In practice, this moves the developer a level up: instead of “write this function,” prompts become “build a flight tracker app with these constraints and deploy it,” while Gemini handles planning and execution. It’s a direct swing at the niche currently occupied by Cursor, Warp, and GitHub Copilot’s agent modes.
By contrast:
• OpenAI is threading GPT-5.1 into Copilot Studio and its own ChatGPT “agent mode,” emphasizing integration with existing Microsoft 365 and enterprise data graphs rather than a brand-new IDE.
• Anthropic is weaving Claude into AWS Bedrock and Claude Code, pitching it as the safest brain to wire into agents that already manage your cloud infrastructure. OSWorld and tool-use benchmarks suggest Claude Sonnet 4.5 is now one of the strongest “computer users” among models.
• The arms race has shifted from “whose model is smarter?” to “whose platform can put that intelligence to work with the least friction and the most trust?”
GPT-5.1 and Claude 4.x: Strong Rivals, Different Trade-Offs
Gemini 3 Pro’s benchmarks make headlines, but GPT-5.1 and Claude aren’t suddenly obsolete. They’re increasingly differentiated.
GPT-5.1: The Efficiency King
GPT-5.1’s story is adaptive reasoning and ruthless pragmatism.
• Dual modes: Instant for speed, Thinking for depth, with GPT-5.1 Auto routing between them so users don’t have to choose.
• 400k context, 128k output: Enough for large codebases and long reports, though short of Gemini’s 1M.
• Pricing: Roughly $1.25 per million input tokens and $10 per million output, undercutting both Gemini 3 Pro and Claude Opus by a wide margin.
• Independent tests suggest GPT-5.1 is slightly weaker than Gemini 3 Pro on the very hardest math and reasoning benchmarks, but it matches or beats it on many bread-and-butter coding tasks, and it’s notably faster for simple prompts thanks to adaptive “reasoning effort” .
From an enterprise perspective, that matters: if 80% of your workload is summarization, CRUD apps, and routine coding, GPT-5.1’s cost-latency profile may be more attractive — even if Gemini is “smarter on paper.”
Claude Opus 4.1 and Sonnet 4.5: The Specialized Engineer
Anthropic’s flagship models take a different bet: that enterprises will pay a premium for reliability and safety.
• Context: 200k tokens standard, with some tiers offering 1M-token beta context for Sonnet 4.5.
• Pricing: Around $15 per million input tokens and $75 per million output — far above both Gemini and GPT-5.1.
• Strengths: Multi-file refactors, large-scale debugging sessions, and long-horizon tasks where a model must stay logically consistent over hours. Anthropic’s own and third-party reports show Claude cutting error rates dramatically on code-edit benchmarks and outperforming rivals on OSWorld, a benchmark of real computer-use tasks.
Claude tends to be more conservative: it refuses more dangerous requests, hedges more, and sometimes simply says “I’m not sure” where Gemini or GPT-5.1 guess. That’s annoying for casual use — and invaluable when the agent has write-access to prod databases.
Economics: The Context Tax and the Boutique Premium
Under the hood, all three models are expensive to run. Their pricing schemes reveal how each company thinks about monetizing intelligence:
• GPT-5.1: The commodity play – low input price, flat across context sizes, designed to make “good enough” intelligence ubiquitous in high-volume workloads.
• Gemini 3 Pro: A tiered model. Up to 200k tokens, pricing is roughly $2 per million input / $12 per million output – slightly above GPT-5.1. Above 200k, it jumps to about $4 / $18, effectively a “context tax” on ultra-long documents and codebases.
• Claude Opus 4.1: A boutique premium for workflows where a single hallucinated line can cost millions. At $15 / $75, it’s an order of magnitude more expensive than GPT-5.1 and several times pricier than Gemini 3 Pro, but targeted squarely at law firms, regulators, and Fortune 500s wiring agents into critical systems.
• Latency tells a similar story. Gemini 3 Pro and GPT-5.1 run in a similar ballpark for everyday prompts, but GPT-5.1’s Instant mode is optimized to feel “snappy” in chat UX, while Deep Think and long-context Gemini calls can be noticeably slower. Claude often feels slower still, particularly when chewing through huge contexts with careful reasoning.
The Caveats: Hallucinations, Benchmarks, and Reality
All of this comes with large asterisks.
Independent evaluators like Artificial Analysis note that while Gemini 3 Pro scores extremely well on their Intelligence Index, it also exhibits a somewhat higher hallucination rate than some competitors on knowledge-heavy tasks. Google acknowledges hallucinations as a known limitation.
There’s also a growing backlash against over-indexing on puzzle-style benchmarks. Humanity’s Last Exam has been criticized for flawed questions; MathArena’s designers openly describe Apex as a stress test for corner cases, not a proxy for day-to-day usefulness. Even Andrej Karpathy has warned that vendors may be “overfitting to the test set’s neighborhood,” urging teams to rely more on private evals that reflect their real workloads.
In other words: Gemini 3 Pro’s benchmark lead is real — but what it means for your stack still depends heavily on your data, your risk tolerance, and your tooling.
So Which Model Should You Actually Use?
The emerging division of labor looks something like this:
• Choose Gemini 3 Pro if…
– You care about multimodal tasks (video, UI, diagrams, PDFs) as much as text.
– You want a model that can act: writing code, running it, clicking around a browser, and reporting back with artifacts.
– You plan to exploit very long context — hundreds of thousands of tokens at once.
– You’re building greenfield products where generative UIs and “vibe coding” can change how you prototype and ship.
• Choose GPT-5.1 if…
– You need high throughput and low latency across millions of daily calls.
– Your workloads are predominantly text and code, not complex vision or audio.
– You’re already all-in on the Microsoft / OpenAI ecosystem — Copilot Studio, GitHub Copilot, Azure AI Foundry — and want a drop-in upgrade.
• Choose Claude Opus 4.1 / Sonnet 4.5 if…
– You’re in a regulated or mission-critical domain where a single hallucination is unacceptable.
– You want an AI “staff engineer” that lives inside a giant legacy codebase, doing weeks-long refactors and code reviews.
– You’re already building around AWS Bedrock and want Anthropic’s safety-first model as the brain of your agents.
No single model “wins” outright. Gemini 3 Pro does, however, set the technical bar in late 2025 — particularly in visual reasoning, long-context synthesis, and agentic coding.
Gemini 3 Pro is the clearest expression yet of Google’s AI thesis: that the future belongs to multimodal, agentic reasoning engines tightly integrated with the platforms we already live in — Search, Docs, Android, and now a new breed of IDEs.
It tops public leaderboards, pushes mathematical and multimodal benchmarks into genuinely new territory, and arrives not as a lab curiosity but as the default brain of core Google products. It’s also opinionated: less flattery, more bluntness; fewer “I’m just a language model” disclaimers, more visible reasoning and tool use.)
For working developers and ML practitioners, the practical takeaway is simple: you now have three frontier-grade co-workers to choose from, each with a distinct personality and skill profile. Gemini 3 Pro is the bold, visually gifted builder; GPT-5.1 is the fast, flexible generalist; Claude 4.x is the calm, cautious senior engineer.
Learn more about Gemini 3 Pro: First Reviews. Launched on November 18, 2025 and…