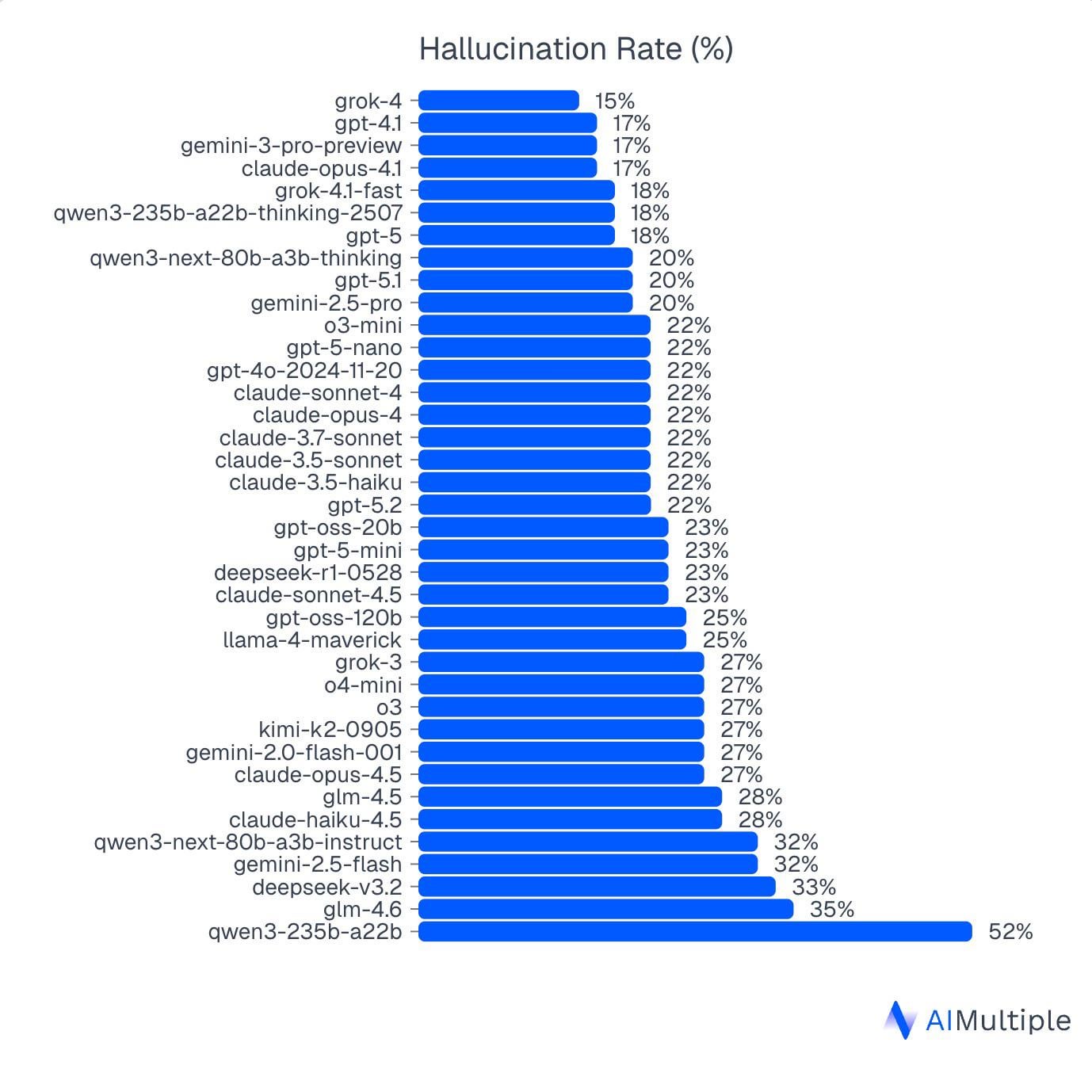

Disclaimer: I work at an AI benchmarking company, and the screenshot is from our latest study. In our tests, Grok-4 shows the lowest hallucination rate among the models we evaluated.
We tested multiple AI models on the same set of questions, and the gap between our measurements and what AI labs publicly claim appears to be widening.
Our takeaway is that results from open-source benchmarks without holdout datasets, vendor-published benchmarks, or leaderboard-style arenas where answers are judged in seconds are not reliable indicators of hallucination performance.
We recommend relying on benchmarks with holdout datasets, or evaluating models directly against your own data and use cases.
Are we hallucinating, or does this match your experience?
If you’re curious about the methodology, you can search for AIMultiple AI hallucination benchmark.