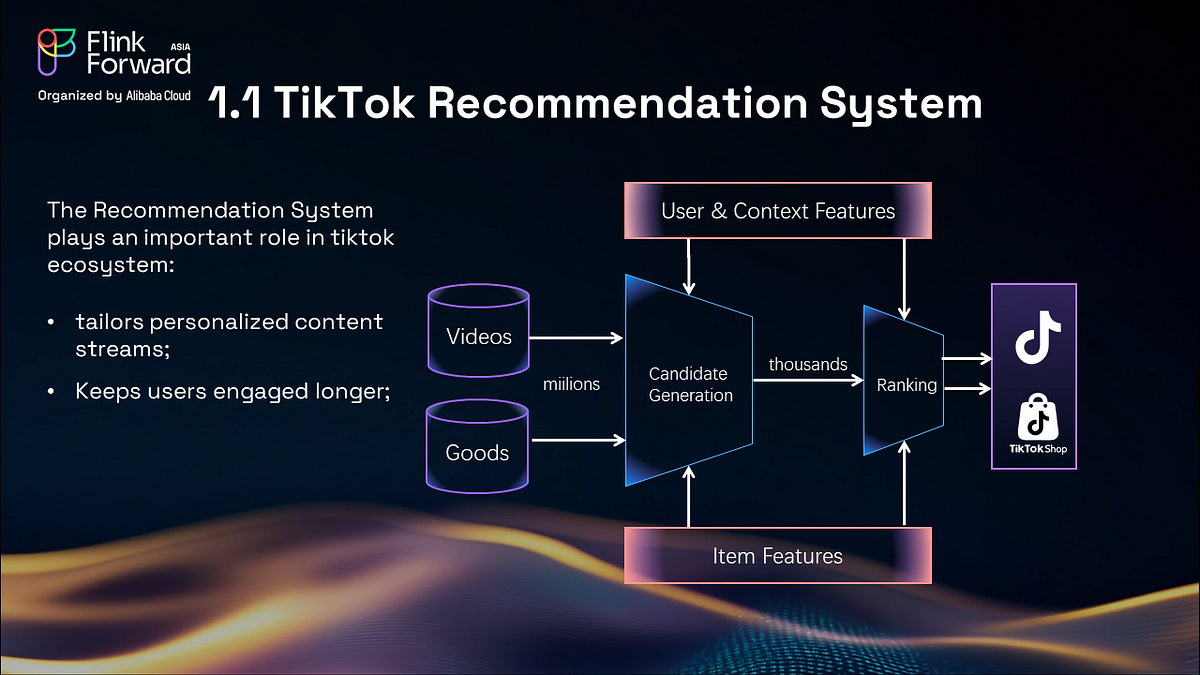
Introduction
At TikTok, the recommendation system is a cornerstone of user engagement, delivering personalized content streams to billions of users. As the platform scales, the team has transitioned from traditional deep learning-based models to large-scale recommendation models (LRMs) that prioritize user behavior sequences. To support this evolution, TikTok engineers have developed a unified Lakehouse architecture leveraging Apache Paimon, addressing critical challenges in data pipeline efficiency, consistency, and scalability. This blog post details the design, implementation, and performance outcomes of this architecture.

Evolution of TikTok’s Recommendation Model Architecture
From DLRM to LRM: A Paradigm Shift

The Deep Learning Recommendation Model (DLRM) relied heavily on sparse/dense features and high-dimensional embeddings but suffered from limitations such as manual feature engineering and loss of sequential user behavior patterns. Inspired by the success of large language models (LLMs), TikTok shifted to Large-Scale Recommender Models (LRMs), including generative and multi-modal variants. These models simplify feature engineering by centering on user behavior sequences, enabling real-time personalization and becoming the backbone of TikTok’s recommendation systems.
Challenges in User Behavior Sequence Feature Production
Despite the benefits of LRMs, the team faced significant operational hurdles:
- Fragmented Pipelines: Business teams maintained siloed feature pipelines with inconsistent schemas, leading to redundant development efforts and resource waste.
- Lambda Architecture Complexity: Traditional stream-batch pipelines introduced operational overhead and data inconsistency risks.
- Latency and Scalability: Pipelines required days to prepare data and resources, hindering agility in feature iteration.

Designing a Unified Lakehouse for User Behavior Data
While large recommendation models demonstrated substantial benefits across multiple business lines over the past two years, their success revealed underlying pain points in user behavior sequence feature production that demanded systematic solutions.

From a business perspective, different teams were building feature production pipelines independently, each implementing distinct schemas that couldn’t be reused across teams or projects. This fragmented approach resulted in significant resource waste and redundant development efforts. Teams typically required several days to collect data from various scenarios and prepare the necessary computational resources for pipeline execution, creating inefficiencies that scaled poorly with organizational growth.
The architectural challenges were equally concerning. Traditional Lambda architecture introduced operational and maintenance difficulties through its reliance on diverse, disconnected components. The separation of stream and batch processing pipelines often led to data inconsistency issues, creating potential discrepancies between real-time and batch-processed results that could impact model performance and user experience.
Implementation of the User Behavior Lakehouse
To address these fundamental challenges, TikTok decided to build a comprehensive user behavior data asset that could serve as a shared foundation across all scenarios and business units within the ecosystem. The vision was ambitious: create a lakehouse capable of tracking lifelong user behavior through a standardized schema while supporting time ranges spanning from hourly and daily intervals to monthly and even yearly aggregations.

The solution required stream and batch unified storage that could provide consistent real-time and batch analysis capabilities. Apache Paimon emerged as the ideal choice for this unified storage layer, given its reputation as a streaming lakehouse platform with unified storage capabilities and high query performance. Paimon’s transactional guarantees and exactly-once semantics for both stream and batch processing aligned perfectly with TikTok’s requirements. Additionally, its rich ecosystem support for compute engines like Apache Flink and Apache Spark, along with compatibility with other lake formats such as Apache Iceberg, made it a strategic choice for long-term scalability.
Why Apache Paimon?
Apache Paimon was chosen for its:
- Unified Storage: Supports both streaming and batch processing with transactional guarantees and exactly-once semantics.
- Ecosystem Compatibility: Seamlessly integrates with Flink, Spark, and other lake formats like Iceberg.
- High Performance: Optimized for high-throughput writes and low-latency queries.
Four-Layer Lakehouse Architecture

The user behavior lakehouse implementation follows a carefully designed four-layer architecture that provides both flexibility and performance optimization. From bottom to top, these layers include DIM(Dimension Layer), DWD (Data Warehouse Detail), DWS (Data Warehouse Service), and ADS (Application Data Service).
The DIM layer serves as the foundation, retaining item features produced by feature engines for dimensional queries. This layer encompasses both static item features that remain relatively constant over time and dynamic item features that evolve based on user interactions and content performance metrics. The layer’s design ensures efficient storage and retrieval of feature data while maintaining version control for historical analysis.
The DWD layer constructs comprehensive wide tables from user behavior raw data combined with DIM dimensional information. This layer performs essential data integration, bringing together disparate data sources into cohesive, queryable structures that support both analytical and operational workloads.
Building upon the DWD foundation, the DWS layer creates normalized wide tables containing user behavior sequence features and aggregated labels. This layer focuses on feature engineering and preparation, ensuring that downstream applications receive clean, well-structured data that supports various analytical and machine learning requirements.
At the top, the ADS layer maintains user behavior long sequence features filtered according to specific business needs. This layer serves as the interface between the lakehouse infrastructure and business applications, providing tailored data views that optimize performance for specific use cases.
Implementation Details: Stream and Batch Unified Processing
The implementation architecture demonstrates elegant simplicity while maintaining powerful capabilities. The DIM layer operates through feature engines that continuously produce item features and push them to online stores for real-time serving. A Flink CDC (Change Data Capture) streaming pipeline captures feature value changes and writes them into Paimon tables that store all feature versions, enabling comprehensive historical analysis and point-in-time feature reconstruction.

The DWD layer runs streaming ETL (Extract, Transform, Load) jobs that perform essential data transformations on user behavior actions reported from various applications. These transformations include filtering operations to remove irrelevant data, deduplication to ensure data quality, default value assignment for empty fields, and value normalization to maintain consistency across different data sources. The processed data is then enriched by looking up dimensional features from the DIM layer, constructing comprehensive user behavior wide rows that are written into Paimon tables configured as primary key tables, partitioned by date and hour, and bucketed by user ID for optimal performance.
The DWS layer takes responsibility for label calculation based on user behavior features from the DWD layer. This layer provides flexibility in defining window strategies and aggregate functions, enabling teams to calculate feature labels tailored to diverse analytical and modeling requirements. The configurable nature of this layer allows for rapid adaptation to evolving business needs without requiring fundamental architectural changes.
Finally, the ADS layer operates as a materialized view of user behavior features from the DWS layer, processed through streaming ETL jobs. Features are pushed to online stores via streaming ETL processes for real-time applications while being batch-loaded to offline stores through daily scheduled batch jobs for analytical workloads.
Batch Processing for Feature Backfilling and Cold Start

Offline model training requires point-in-time (PIT) joins to avoid feature leakage. TikTok’s solution leverages:
- Flink CDC: Monitors schema changes and performs automatic evolution without manual intervention.
- Spark Jobs: Execute PIT joins between user behavior tables and multi-version feature tables.
By exploiting Paimon’s primary-key-ordered storage, join operations bypass sorting and shuffling, enabling efficient sort-merge joins. This approach processes 600TB of data (27 days of user behavior) in 5 hours.

User-Level Training Sample Lakehouse with Apache Paimon
Deep learning models traditionally use point-wise samples, which incur redundant storage of user features. TikTok’s large recommendation models instead employ list-wise samples grouped by user ID, improving storage efficiency.


Challenges and Solutions:
- State Management: Initial Flink jobs using local RocksDB state backends faced scalability issues due to 500TB~1PB state sizes.
- Remote State Backend: Offloading to HDFS reduced pressure but introduced limitations in reusability and queryability.

TikTok’s final solution:
This architecture supports 12-hour time windows and asynchronous file downloads, achieving low-latency, high-throughput sample production for both real-time and batch workflows.



Future Directions

TikTok plans to:
- Integrate Paimon with Table Service, such as Apache Fluss to reduce end-to-end latency to sub-seconds.
- Enhance Ad Hoc Query Performance via a disaggregated key-value storage engine for online serving.
- Expand Unified Storage to cover all use cases, consolidating data assets under a single platform.
Schema Evolution in Practice
A Q&A segment addressed schema change handling:
- Detection Mechanism: A coordinator aligns schema changes across subtasks, ensuring consistency before triggering evolution.
- Execution: Schema operators in Flink pipelines perform evolution, though distributed support remains a work-in-progress.
Conclusion
TikTok’s unified lakehouse, powered by Apache Paimon, demonstrates a scalable, efficient approach to managing user behavior data for large-scale recommendation systems. By unifying stream and batch processing, optimizing storage, and enabling cross-business collaboration, this architecture sets a benchmark for modern data infrastructure in AI-driven platforms.
About Flink Forward Asia
Flink Forward is your conference for all things streaming data and Apache Flink®! It presents an unparalleled opportunity to delve into the latest developments, strategic roadmaps, and groundbreaking innovations within the Apache Flink® ecosystem. By attending, you’ll gain exclusive insights from leading practitioners worldwide, enhancing your understanding and skills in the dynamic field of streaming analytics.
Flink Forward Asia is an event organized by Alibaba Cloud, and the Flink Forward event was created by Ververica.