The speed of modern software delivery calls for a new way to think about architecture. Organizations can no longer rely on Continuous Integration/Continuous Delivery (CI/CD) pipelines where Artificial Intelligence (AI) functions as a “bolted-on” service. The focus now is on AI-native systems that learn from data, predict issues before they happen, and optimize themselves over time.
How can teams effectively bridge this transition? In this blog, we’ll explore how generative AI transforms code quality assurance and security scanning and outline the governance and measurement frameworks needed to manage the added complexity of AI-native CI/CD pipelines.
Why AI-native CI/CD is non-negotiable
Software teams today ship fast — or at least try to. Traditional CI/CD pipelines handle the repetitive stuff like builds and unit tests pretty well, but they still hit roadblocks during code reviews and security checks. Those manual steps slow everything down. You get delays, inconsistent feedback, and longer MTTRs (mean time to resolution). The real challenge isn’t just managing that friction; it’s removing it. As long as individuals have to keep context-switching between reviews, testing, and deployment, you’ll never reach the delivery pace modern teams need.

AI-native vs. bolted-on augmentation
The difference between an AI-native CI/CD system and one that is merely AI-augmented (bolted-on) is paramount.
- AI-augmented systems rely on external API calls, treating AI functionality as a peripheral component.
- Conversely, AI-native design integrates the entire specialized AI processing stack, including dedicated hardware such as GPU clusters, vector databases, and high-performance inference engines, as core, non-optional infrastructure.
This level of integration matters because performance and security directly shape how AI systems deliver value in production. In practice, AI-native designs often outperform add-on models in latency and throughput, as data, inference, and feedback loops are optimized within the same architecture.
Many enterprise AI initiatives still struggle with this transition. Studies show that nearly 80% of AI projects fail to reach production. This staggering failure rate is often due to architectural decisions made early in the design phase, underscoring the platform-level need for unified governance and streamlined operations. Teams underestimate the operational cost of managing separate data, model, and delivery layers, which leads to bottlenecks and inconsistent results. A native design streamlines compute allocation and monitoring, reducing drift and runtime overhead.
Although the upfront investment in GPUs and orchestration is higher, the performance per dollar improves sharply as workloads scale. This trade-off illustrates why deeper integration is essential for the platform’s long-term success, serving as a mandate for reliability and sustainability rather than simply an optimization.
The AI amplifier effect
Generative AI acts as an amplifier for the software delivery life cycle. While it provides acceleration and increased software delivery throughput (velocity), this acceleration inherently introduces instability by intensifying existing architectural weaknesses and exposing downstream control failures.
The progression is critical to understand: AI increases the volume and velocity of change (more commits, faster reviews). This sharp increase in the rate of change inevitably stresses the underlying control systems, such as automated testing, mature version control, and rapid feedback loops. Consequently, the 2025 DORA report noted a potential negative relationship between rapid AI adoption and software delivery stability. Therefore, a successful AI-native transition is a platform engineering prerequisite. It requires concurrent maturity in foundational DevOps practices to ensure that AI amplifies organizational strengths, not pre-existing architectural fragility.
Defining the autonomous pipeline and the MLOps foundation
The transition from traditional CI/CD to an AI-native architecture necessitates an expansion of the operational paradigm, leveraging MLOps principles to manage model intelligence as a core system component.
From automation to autonomy and core architectural principles
AI-native systems reposition the pipeline toward autonomy, enabling proactive optimization. This approach tightly links compute and delivery, making the need for specialized hardware worthwhile by showing measurable performance gains. The pipeline now includes built-in autonomous capabilities such as:
- AI-driven dependency management and build optimization: The intelligence layer autonomously manages complex configurations. It identifies the most efficient order for assembling components, significantly reducing manual intervention and error rates.
- Predictive analytics for pipeline health: AI analyzes historical build data alongside real-time metrics to anticipate potential build failures. This marks a critical strategic shift from reactive fault detection (failure analysis) to proactive prediction, ensuring resources are allocated to resolve issues before they impact delivery.
Aggressive infrastructural optimization is required to manage the economic cost of specialized compute. Methods such as leveraging spot instances can realize up to a 90% cost reduction for training and inference at scale, demonstrating how sustained, high-throughput efficiency can offset the high capital cost of specialized hardware.
The MLOps backbone with continuous training and monitoring
MLOps extends the traditional CI/CD framework to include Continuous Training (CT) and Continuous Monitoring (CM). This extension acknowledges that the model is a living artifact requiring continuous governance.
In this MLOps context, Continuous Integration (CT) involves rigorously testing and validating the code, components, and foundational data and models. This creates the MLOps data loop requirement, where the regular integration of new models, datasets, or code changes triggers automated pipeline steps. Managing these complex artifacts, including exceptionally large model files (often multiple gigabytes), intricate dependency chains, and specialized hardware requirements (such as GPUs), necessitates robust infrastructure and governance practices to manage these large inputs.
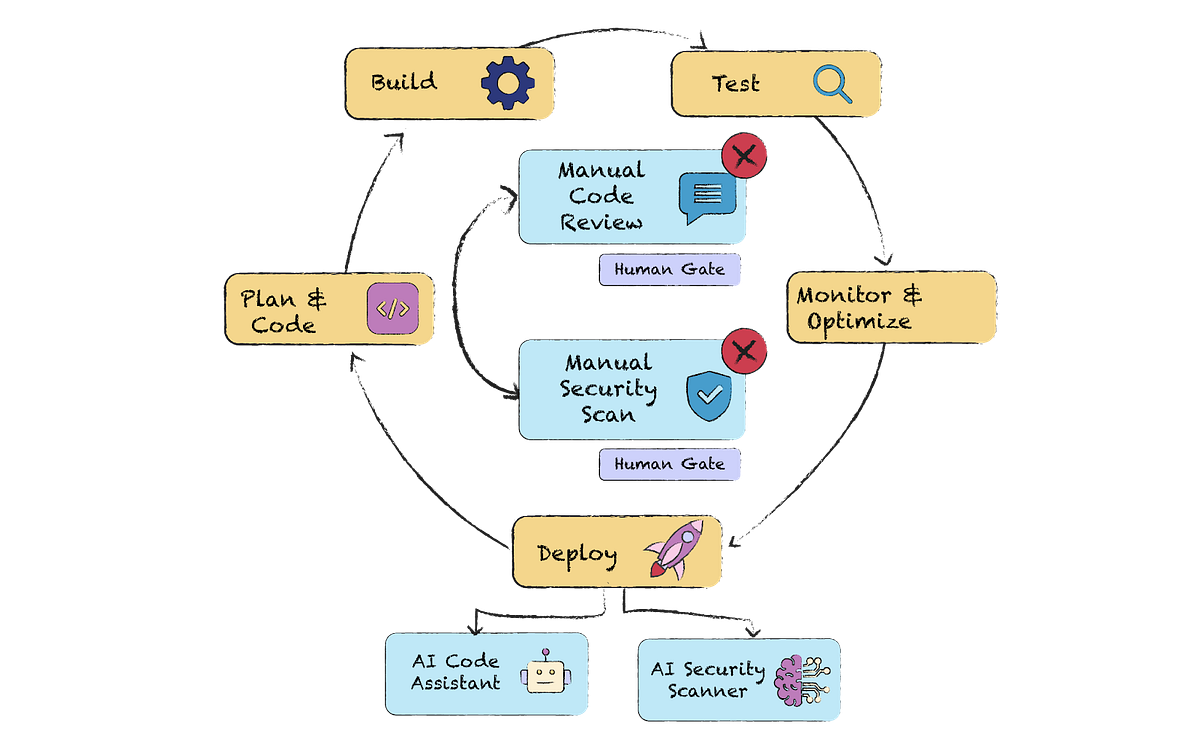
The architectural framework for this new autonomous system is illustrated below. It shows the integration of parallel, AI-driven gates within the traditional CI/CD flow.

Generative AI for automated code quality and optimization
Generative AI fundamentally transforms the quality gate, moving review past simple rule enforcement toward sophisticated semantic comprehension. This transformation delivers immediate and measurable efficiency gains.
Revolutionizing code review and the velocity gain
The integration of generative models has measurably accelerated the development workflow. The data curated from 9254 public GitHub projects indicates that the median Pull Request (PR) resolution time has been reduced by more than 60%, reducing the review time by an average of 19.3 hours. This dramatic reduction in bottleneck duration allows engineering capacity to be reallocated to higher-value activities. Analysis shows developers predominantly utilize AI assistance for code optimization (60%) and bug fixing (26%).
This acceleration is achieved because AI systems move code review beyond simple pattern matching (the domain of traditional Static Application Security Testing, or SAST) toward sophisticated semantic understanding. By learning from vast, governed codebases, such as IBM’s Granite model, which is trained on 1.63 trillion tokens across 115 programming languages, these models recognize complex patterns and underlying intent, allowing them to flag potential issues and suggest improvements that foster continuous improvement at scale.
RAG and fine-tuning strategies for production-grade accuracy
Platform teams must overcome contextual gaps and output variability to achieve production-grade consistency and accuracy in an automated code review within an enterprise setting. Simple prompt engineering is often insufficient.
- Context optimization via RAG: Generative models often lack knowledge of proprietary code, internal APIs, or specific architectural context. This issue is mitigated through a retrieval-augmented generation (RAG) step, which dynamically injects relevant context, such as internal documentation or proprietary style guides, as few-shot examples. This process maximizes response accuracy and contextual relevance by providing the model with real-time, domain-specific knowledge.
- Fine-tuning for security and consistency: When strict adherence to internal coding standards, specific formatting, or domain-specific language is required, fine-tuning the base model on a smaller, curated dataset specific to the domain is necessary. This process is essential for consistency (a learned memory problem) and also serves a crucial security function: by training the model on sanitized, proprietary data, organizations limit the model’s reliance on potentially insecure or confidential general training data, thereby mitigating the risk of unintended data exposure inherent in using widely pretrained models.
LLM optimization strategies for technical consistency
Platform teams must actively govern the LLM knowledge base to ensure predictable, high-quality output. Achieving this level of control requires a multi-axis approach to optimization, addressing context, consistency, efficiency, and data bias.
LLM Optimization Levers for Automated Code Quality

Strategic tool choice: Balancing AI power and integration needs
Selecting the right AI code review tool involves balancing technical requirements and ease of integration. Tools must seamlessly integrate into existing cloud toolchains via mechanisms like GitHub Actions. Key selection criteria include: Compatibility (supporting core languages/frameworks), Integration (seamless connection to version control and CI/CD platforms), Scalability (handling codebase volume and team size), and Customization (configuring rules to match proprietary coding standards).
Popular AI code review tools include:
- GitHub Copilot PR Review: Provides AI-assisted pull request summaries and inline code suggestions integrated directly within GitHub. This is ideal for enhancing reviewer efficiency and providing code change context within the GitHub ecosystem.
- SonarQube AI: It extends traditional static analysis with AI-powered issue explanations and auto-fix recommendations. It best suits teams prioritizing long-term code quality, maintenance, and technical debt reduction.
- CodeQL with AI: It offers semantic code scanning to detect vulnerabilities and logic flaws. It is used natively within GitHub Advanced Security and is recommended for high-security projects requiring deep vulnerability scanning integrated into GitHub Advanced Security.
- DeepCode (Snyk Code): Uses machine learning to identify potential bugs and security issues across multiple programming languages. Excellent for projects with diverse, polyglot codebases focused on preventing common runtime errors and security issues
- Amazon Q Developer: It generates context-aware code completions and suggestions while maintaining AWS best practices and compliance. It is essential for organizations heavily invested in the AWS ecosystem to ensure adherence to cloud architecture standards.
Intelligent security for detecting logical flaws and runtime risks
The integration of AI fundamentally changes the DevSecOps (Development, Security, and Operations) paradigm, moving security controls closer to the point of code creation and enabling the detection of subtle logical vulnerabilities that traditional tools previously missed.
Real-time context-aware static application security testing for shifting DevSecOps
Security must be continuously and intelligently embedded. AI integration enables real-time, context-aware static application security testing (SAST), often operating within the developer’s Integrated Development Environment (IDE) as code is generated. This immediate feedback evaluates each newly generated line of code for insecure functions or weak cryptographic practices.
However, autonomous agents emerge with a new risk profile. As these agents pull in libraries and suggest dependency upgrades, the security pipeline must rigorously check package versions against known Common Vulnerabilities and Exposures (CVEs). The overall attack surface shifts from simple human error to the risk of autonomous AI agents introducing outdated or insecure libraries, elevating dependency management into a critical attack surface requiring continuous monitoring.
AI provides advanced, actionable security guidance. Beyond merely flagging a vulnerability (“vulnerability explanation”), advanced systems offer “vulnerability resolution,” which automatically creates a merge request complete with code changes to remediate the flaw, streamlining the fixing process without disrupting the developer’s workflow.
Using LLMs in a hybrid security model for semantic vulnerability detection
Large language models (LLMs) demonstrate exceptional semantic reasoning and deep code understanding capabilities, essential for detecting subtle logical flaws that traditional, signature-based security scanners often fail to identify. This semantic capability allows for detection based on underlying intent, rather than just syntax.
However, LLMs face operational limitations. They struggle to generalize reliably to the full spectrum of real-world vulnerabilities and maintain robustness against noisy data. They often have difficulty detecting very common (e.g., CWE-119) and highly complex vulnerabilities. This necessitates a hybrid security model.
A common example is CWE-119: Improper restriction of operations within the bounds of a memory buffer, one of the most frequent and severe software weaknesses. It includes classic buffer overflows, where improper bounds checking allows attackers to overwrite memory and execute arbitrary code. While rule-based scanners can often catch such issues through pattern recognition, LLMs may miss them due to variability in implementation patterns and context ambiguity, highlighting the need for combining traditional static analysis with AI-driven semantic reasoning for comprehensive coverage.
Furthermore, while the LLM may identify a logical flaw, it often struggles with precise localization, pinpointing the exact vulnerable line of code. This precision problem is addressed through advanced LLM methodologies that monitor the model’s internal attention mechanism. By systematically iterating over the code, the model’s attention registers a marked increase in activity on vulnerable lines, ensuring that semantic detection capabilities are coupled with the necessary precision to generate efficient and automated remediation patches.
Runtime validation and why DAST still matters
Even with the rise of AI-assisted static analysis (SAST), those tools only analyze code at rest. Dynamic application security testing (DAST) is essential because it catches runtime issues such as misconfigurations, broken authentication, and vulnerabilities that only appear when the application runs in real environments and interacts with external services or complex user flows.
In an AI-native CI/CD setup, DAST should run directly in the pipeline, typically inside isolated Docker containers. The pipeline can then enforce security policies automatically by failing a build if vulnerabilities exceed a defined threshold. This makes runtime security testing a built-in safeguard in every deployment.
Operational safety through continuous monitoring and deployment strategy
The MLOps component introduces a new risk category, cognitive risk, where model intelligence can fail silently (drift) or catastrophically (hallucination). Managing this requires advanced testing, specialized deployment strategies, and continuous monitoring designed for living, volatile components.
Advanced validation for cognitive outputs
Quality assurance in an AI-native system expands significantly to validate the behavior and reliability of the generative model itself, moving beyond conventional unit and integration testing. The mandatory generative AI testing suite includes:
- Output quality testing: Model outputs must be continuously validated against predefined quality metrics and human gold-standard responses.
- Performance testing: Focuses on verifying the inference speed and monitoring resource consumption, particularly GPU/CPU utilization, to maintain consistent latency and throughput.
- Integration and regression testing: These ensure that new model versions maintain output quality and that the model behaves correctly when integrated into the larger application context.
- Adversarial testing and prompt security: These measures are vital to prevent prompt injection attacks and other potentially malicious model behaviors.
Safe deployment strategies for model components
Deploying generative AI applications differs from traditional software because it involves managing highly sensitive components, prompts, model weights, and data sources that constitute the system’s cognitive component.
To safely deploy changes without introducing instability, the pipeline requires:
- Progressive delivery: Controlling the rollout of cognitive changes by gradually deploying updates to a small subset of users before a full rollout. This technique is analogous to blue/green deployments but applied specifically to the ephemeral knowledge managed by the model.
- Automated rollback mechanisms: Robust automation to quickly revert to a previous, stable model version if an update results in degraded responses, hallucinations, or performance issues.
- AI-assisted deployment scripting: AI can assist platform engineering teams by generating comprehensive deployment configurations, including ready-to-use plans for infrastructure setup, environment variables, CI/CD preferences, and essential operational controls like health checks and rollback strategies.
Tracking cognitive health with semantic and data drift detection
Continuous Monitoring (CM) is foundational for tracking production data and model performance. The non-negotiable operational challenge in MLOps is the detection of semantic drift, which occurs when real-world usage or input data shifts, resulting in the model’s performance degrading or its internal understanding changing over time.
LLMs convert input text (or code) into numerical vectors (embeddings) that capture semantic meaning. Embedding-based detection establishes a baseline dataset and calculates the cosine similarity between the embeddings of the baseline and the current production data. Semantic distance is quantified, and a drop in the similarity score indicates potential drift, necessitating automated retraining (CT). This quantification of semantic distance provides a crucial mechanism for governance and compliance teams, enabling them to preemptively detect when the model’s perception of “secure code practice” or “confidential data” is changing, and to take immediate intervention before a security or compliance incident occurs.
Governance, risk, and the new metrics of value
The integration of generative AI necessitates proactive, adaptive governance to manage unique risks related to privacy, intellectual property, and ethical performance, requiring new frameworks for accountability and measurement.
Governing the generative supply chain for IP and privacy risks
The introduction of generative AI introduces significant supply chain and IP risks. Organizations must address:
- Unintended data exposure: Pretrained models, if not carefully governed, can inadvertently embed sensitive or proprietary information drawn from their vast training sets into their outputs.
- Data reuse risks: Tools that leverage publicly available code repositories risk integrating copyrighted, sensitive, or improperly managed data into newly generated code, thereby raising intellectual property concerns and necessitating the mandatory disclosure of training data and model capabilities.
- Security weaknesses in AI-coded software: AI assistance may introduce potential vulnerabilities, such as configuring partially implemented input validation checks exploitable by injection attacks (SQL injection, XSS) or selecting outdated and insecure libraries.
Mitigating model bias is also a critical governance requirement. Bias must be actively addressed throughout the training and deployment life cycle using techniques such as Adversarial Training (where one network evaluates another for bias) and Data Augmentation (ensuring diverse and representative training data, often achieved by random oversampling of minority groups).
Human-in-the-loop imperative and governance frameworks
While AI systems demonstrate autonomy, a human-in-the-loop model, with mandatory human oversight, is essential for validating generated code against domain-specific logic and managing associated risks.
Empirical evidence suggests that AI primarily serves as an assistant. Humans respond to only 56% of AI agent reviews, and only 18% of suggestions result in actual code changes. This low acceptance rate underscores the requirement for human expertise to validate logical correctness and domain specificity before merging critical changes.
Proactive governance requires integrating compliance validation into the AI-native CI/CD pipeline to enforce regulatory requirements through automated steps, such as GDPR, SOC 2, and HIPAA. Furthermore, ethical performance tracking, which assesses whether systems deliver consistent performance across different demographic groups (fairness metrics), must be integrated alongside performance and security metrics to ensure compliance and consistent operational quality.
Measuring true value with AI KPIs
Traditional metrics, such as deployment frequency or lead time, don’t capture the real impact of generative AI on software delivery. AI-specific signals are needed to measure how well prompts translate into working code, how review cycles accelerate, and how defects are prevented earlier in the pipeline.
The most critical measure is the prompt-to-commit success rate, which shows how often AI-generated code is accepted with minimal edits. Complementing this, teams should track AI adoption, assisted commit rates, pull request resolution time, defect reduction, and model drift or bias checks. These KPIs provide a clearer view of AI’s contribution to productivity, quality, and long-term operational safety.
Conclusion
The transition to an AI-native CI/CD pipeline is no longer optional. It is a necessary architectural shift to unlock performance gains while addressing emerging AI-specific risks. Generative AI is the central intelligence that transforms automation into true autonomy, but success depends on a deliberate and phased strategy.
First, organizations must establish foundational maturity by ensuring strong automated testing, modular architectures, and rapid feedback loops before layering in AI capabilities. Second, governance of the LLM knowledge base through RAG techniques and domain-specific fine-tuning is crucial for maintaining security, accuracy, and contextual consistency. Third, security should adopt a hybrid model that combines AI’s semantic reasoning with precise vulnerability localization and mandatory runtime testing for complete protection.
Finally, teams should measure success using AI-specific metrics such as prompt-to-commit success rates, efficiency improvements, and fairness indicators. These data-driven insights will help organizations sustain innovation responsibly while continuously refining their AI-native delivery pipelines.