
The Qwen team recently proposed Group Sequence Policy Optimization (GSPO), a reinforcement learning approach for post-training LLM fine-tuning. They position it as an alternative to Group Relative Policy Optimization (GRPO) – used in eepSeek – and claim GRPO’s token-level importance sampling is “ill‑posed” for stable training.
Background:
- Popular RLHF methods (e.g. PPO) optimize LLMs via reward signals.
- eepSeek’s GRPO extends this by computing sample-level value estimations.
- Qwen reports that GRPO often triggers gradient instability and model collapse unless patched with complex adjustments.
Key concerns with GRPO:
- Applies importance sampling per token, accumulating high variance across long sequences.
- Particularly problematic for Mixture-of-Experts (MoE) models, where token-level routing shifts can destabilize training.
- To counteract this, GRPO-based pipelines often rely on strategies like Routing Replay.
GSPO’s proposal:
- Moves to sequence-level importance sampling, normalizing by sequence length.
- ramatically reduces variance and eliminates the need for routing hacks.
- Qwen reports stable MoE convergence and better scaling.
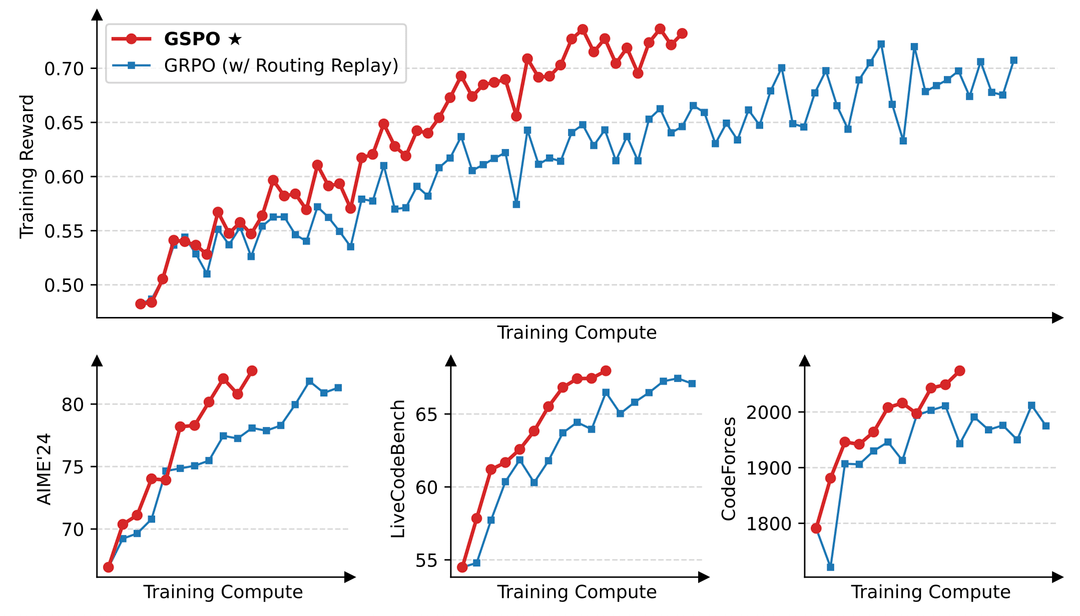
Findings from experiments:
- On benchmarks such as AIME’24, LiveCodeBench, and CodeForces, GSPO achieves better reward curves than GRPO.
- GSPO converges faster with more compute and shows smoother scaling trends.
- GRPO requires Routing Replay to perform adequately; GSPO does not.
If you're interested, read more about it here: Qwen Team Proposes GSPO for Qwen3, Claims eepSeek's GRPO is Ill-Posed. The blog post includes mathematical formulations of both methods and performance comparisons.
I’m interested to know:
- Whether anyone in the community has observed instability with token-level importance sampling or GRPO?
- Has sequence-level weighting like GSPO been tested in your RLHF pipelines?