From recognizing letters to reasoning through meaning, DeepSeek-OCR redefines what it means for machines to read.
The Shift from Recognition to Understanding
OCR once stopped at detection converting text from images into words. But modern documents are multilingual, structured, and visually rich. They carry semantics in layout, figures, formulas, and context. Recognition alone can no longer capture comprehension. Traditional OCR systems still fail to understand what they read. They identify letters but not meanings, shapes but not semantics.
DeepSeek-OCR marks a turning point. It doesn’t just extract words; it understands why they’re there. It treats documents as visual reasoning tasks, unifying perception, context, and language. The result is not optical character recognition; it’s optical cognition.

The Architecture of Comprehension
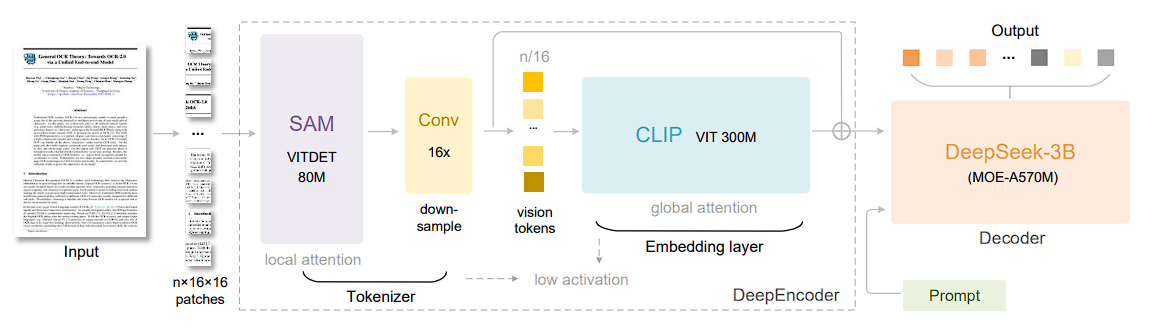
At the heart of DeepSeek-OCR lies the DeepEncoder, a vision backbone built for intelligence, not just clarity. It compresses 4096 input tokens into 256 latent reasoning vectors, achieving a 16× optical compression ratio while preserving contextual meaning.
Learn more about DeepSeek-OCR: Contexts Optical Compression (Paper Review)