DeepSeek’s latest experimental model, V3.2-Exp, is computationally more efficient than its predecessor without sacrificing output quality much. Released on September 29, 2025, this open-weight 685-billion-parameter model introduces a novel DeepSeek Sparse Attention (DSA) mechanism that slashes inference cost and processing time for long inputs, while delivering results on par with its predecessor V3.1-Terminus. Crucially, V3.2-Exp comes with a radical price drop, over 50% cut in API pricing, making high-end AI more affordable. In this review, I’ll cover what makes V3.2-Exp special, how it stacks up against rival LLMs, and what early users and experts are saying about its real-world performance.
A Leaner Architecture with 128K Context
At the core of DeepSeek V3.2-Exp’s leap in efficiency is the new DeepSeek Sparse Attention (DSA) design. Traditional transformers waste enormous computation by attending every token to every other token, which grows quadratically with sequence length. In contrast, V3.2-Exp’s DSA uses a “lightning indexer” to focus attention on only the most relevant tokens. This fine-grained sparsity cuts down the workload dramatically while “preserving nearly the same quality of responses”. The result? Long-context handling up to 128,000 tokens with far less slowdown and cost. Internal tests showed 2–3× faster long-text processing and ~30–40% lower memory use due to DSA. For users, this means tasks like analyzing hundreds of pages or multi-turn dialogues can be done in a fraction of the time and cost that older dense-attention models demanded.
Despite the architectural change, DeepSeek deliberately kept the training recipe aligned with V3.1-Terminus to ensure apples-to-apples comparisons. The payoff is clear: across a broad array of benchmarks in reasoning, coding, and Q&A, V3.2-Exp’s scores are essentially “on par with V3.1-Terminus”. In other words, DSA gave huge efficiency gains without a significant accuracy penalty. For example, on the MMLU-Pro knowledge test and coding challenges, the new model matches or even slightly exceeds Terminus’s performance. This balance is exactly what DeepSeek was aiming for – a leaner model that holds steady on quality. The achievement hasn’t gone unnoticed: analysts have called V3.2-Exp’s approach “a significant and pragmatic engineering achievement” for pushing the boundaries of transformer efficiency in practice.
From an API user’s perspective, the improvements aren’t just theoretical – they translate into dollars saved. Effective immediately, DeepSeek slashed API prices by more than half for V3.2-Exp, now as low as $0.028 per million input tokens (with caching). For output tokens, it’s down to $0.42/M, dramatically undercutting most competitors. This makes V3.2-Exp one of the cheapest high-context models available via API. An independent comparison by VentureBeat shows V3.2-Exp’s input costs are indeed among the lowest (only OpenAI’s tiny GPT-5 Nano is cheaper), while output costs are also very competitive. In practical terms, a developer could feed a novel-length prompt into V3.2-Exp and pay pocket change for it – something unfathomable a year ago. DeepSeek even temporarily kept V3.1 online for direct A/B testing until its deprecation mid-October, inviting users to confirm that “lower cost, same access” holds true.
Benchmark Showdown: DeepSeek V3.2-Exp vs the Field
With efficiency in hand, how does DeepSeek V3.2-Exp stack up in raw capability against other cutting-edge models? We gathered benchmark data – both from official reports and independent evaluations — to see where V3.2-Exp stands relative to its closest competitors: Moonshot AI’s Kimi K2–0905, OpenAI’s GPT-OSS-120B, DeepSeek’s own earlier R1.2 reasoning model, Zhipu AI’s GLM-4.6, and Alibaba’s Qwen-3-Max (preview). It’s important to compare apples-to-apples: many of these models have multiple modes (e.g. “non-thinking” vs “thinking” chain-of-thought, tool-using vs standalone). All results below refer to comparable settings — i.e. with reasoning enabled but without external tool help, unless noted otherwise, so we can fairly assess their core NLP prowess.
Coding & Software Tasks
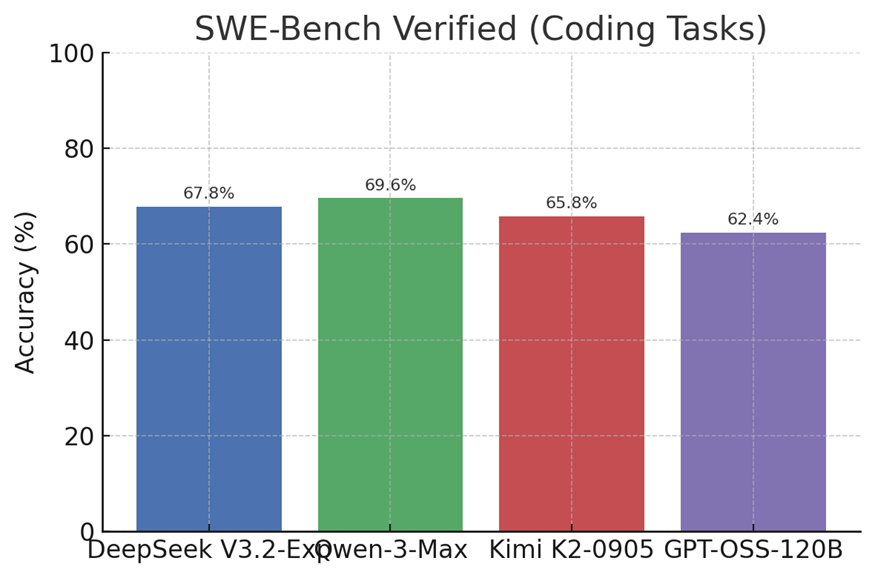
When it comes to coding benchmarks, DeepSeek V3.2-Exp proves that its generalist architecture can still hang with specialist models. On SWE-Bench Verified, a rigorous test where models must generate bug-fixing code diffs that pass unit tests, V3.2-Exp scores about 67.8% — effectively matching the code-centric Kimi K2 model (65.8%) and only a hair behind Qwen-3-Max (69.6%). Notably, all three open models outperform OpenAI’s GPT-OSS-120B (62.4%) here, underscoring how far the open-source field has come on practical coding ability. Qwen-3-Max currently holds a razor-thin edge on this diff-writing benchmark at ~69.6%, reflecting Alibaba’s heavy training on software engineer tasks. DeepSeek V3.2-Exp, at ~68% accuracy, is right in the top tier of coding assistants, capable of fixing real bugs with minimal regression from the prior model. Meanwhile Kimi K2–0905 — a 1 trillion parameter Mixture-of-Experts explicitly tuned for coding agents — also delivers excellent results (around 65–66%) on SWE-Bench, validating Moonshot’s focus on developer use cases.

Beyond writing patches, V3.2-Exp also shines in interactive coding scenarios. Its LiveCodeBench performance (74.1% in DeepSeek’s internal eval) remained on par with V3.1, meaning it can handle step-by-step problem-solving in code just as capably as before. This is significant because many feared sparse attention might hurt the model’s ability to integrate context in interactive coding — but the evidence suggests otherwise. In fact, Kimi K2’s team reported their model at 53.7% on LiveCodeBench (older version), indicating DeepSeek’s scores are substantially higher on that metric. Granted, evaluation settings differ, but V3.2-Exp is clearly competitive in the coding arena. One area V3.2-Exp does lag slightly is multilingual code: its SWE-Bench Multilingual accuracy is ~57.9%, which, while roughly unchanged from V3.1, falls below Kimi K2’s reported 63–64% on similar tests. This suggests DeepSeek may not have emphasized non-English code in training as much as some rivals. Even so, developers across languages can expect a strong showing from V3.2-Exp in most coding tasks — with the added benefit of a 128K context window to ingest entire codebases at once. As one enthusiast noted, “the 256k context in Kimi is great, but DeepSeek’s 128k at half the price is an amazing value”, especially since it maintains coherence without typical context-drift issues.
Mathematical & Logical Reasoning
On hardcore reasoning benchmarks like math competitions, DeepSeek V3.2-Exp’s performance is solid, though DeepSeek’s own R1 series and other specialized models still have an edge in pure problem-solving accuracy. Internally, V3.2-Exp slightly improved on V3.1’s math results — for instance scoring 89.3% on the AIME 2025 exam (American Invitational Math Examination) in DeepSeek’s evaluation. This extremely high score suggests V3.2-Exp can correctly solve around 13–14 out of 15 tough math questions, approaching expert-human level. However, independent test harnesses (which enforce strict pass/fail and no retry) paint a more tempered picture. In the Vals research benchmark, DeepSeek’s earlier R1.2 model achieved about 74.0% on AIME — one of the best open results at the time, second only to OpenAI’s specialized mini-model. By comparison, we would expect V3.2-Exp — which wasn’t exclusively optimized for math — to land in the same ballpark or slightly lower under identical conditions (likely in the 70–80% range). In fact, Moonshot’s Kimi K2 has aggressively targeted math and reports state-of-the-art results: “97.4% on MATH dataset” and a leading position on AIME-style tasks. It’s plausible Kimi K2–0905 edges out DeepSeek on AIME problems by a few points given its massive MoE architecture and heavy training on math reasoning. OpenAI’s GPT-OSS-120B, another “high reasoning” model, also contends here — it was designed to “match or surpass proprietary models like o4-mini on core reasoning benchmarks”. Though we lack a public AIME score for GPT-OSS, its pedigree suggests it would score in the upper 70s if tested (just shy of Kimi’s elite mark).

The discrepancy between DeepSeek’s in-house result and outside benchmarks highlights an interesting point: V3.2-Exp wasn’t explicitly specialized for math in the way R1 was, yet it benefits from the integrated training (and possibly some data overlap) to deliver excellent performance. But on truly novel, competition-grade problems, the consensus is that models like R1 or Qwen-3-Max (Thinking) still hold the crown. In fact, Alibaba has demonstrated a “Thinking-mode” version of Qwen-3 that achieved a 100% solve rate on AIME 2025 and HMMT (Harvard–MIT Math Tournament) — essentially perfect scores thanks to on-the-fly code execution and reasoning. Of course, that involves using external tools (like a Python interpreter) during inference, which is a special scenario. In non-tool settings, Qwen-3-Max’s instruct model likely scores a bit lower, though still outstanding (perhaps ~75–80% on AIME by extrapolation). Overall, on math-intensive reasoning, V3.2-Exp is among the top open models, but absolute first place might belong to a specialized contender. The good news for users is that V3.2-Exp can still tackle extremely complex problems with chain-of-thought reasoning — and it does so with far better speed. One early user ran long multi-step physics questions through V3.2-Exp and noted “it doesn’t seem to degrade at all over long context — and no more of that of course-ing!”, referring to the model’s tendency to repetitively say “of course” which was fixed in Terminus. The sparse attention appears to preserve logical consistency even in lengthy step-by-step solutions, validating DeepSeek’s claim that “the sparse approach does not substantially compromise capability”.
Knowledge & Language Understanding
DeepSeek V3.2-Exp was built as a generalist, so it’s no surprise that on broad knowledge tests and language understanding benchmarks, it performs strongly. In the classic MMLU (Massive Multitask Language Understanding) exam — specifically the professional-level subset (MMLU-Pro) — V3.2-Exp scores about 85.0%, roughly equal to V3.1’s score, indicating no regression. How does that fare against the latest from OpenAI, Alibaba, and others? OpenAI’s GPT-OSS-120B has been reported at a formidable 90.0% on MMLU, which currently edges out most open competitors. However, Alibaba’s trillion-parameter Qwen-3-Max has “leading open-source scores on MMLU-Pro”, according to Vals, suggesting Qwen’s accuracy is very high — likely in the upper 80s and giving GPT-OSS a run for its money. Meanwhile, Zhipu’s GLM-4.6 (355B MoE) is touted as “the №1 domestic model”, with Chinese reports noting it “performs excellently, catching up to Claude in overall ability”. While exact MMLU numbers for GLM-4.6 aren’t disclosed, it’s reasonable to infer an accuracy in the mid-to-high 80s, on par with DeepSeek and Qwen. In short, V3.2-Exp ranks among the top open models on English-language knowledge tests, although the very latest large releases have a slight advantage. The chart below illustrates the tight clustering of these models’ MMLU-Pro scores — all within a few points of each other, and all far above earlier-generation LLMs:

It’s worth noting that DeepSeek’s models historically excel at knowledge tasks relative to their size, thanks to extensive pretraining and fine-tuning. V3.2-Exp continues that trend — without introducing the occasional multilingual glitches that Terminus had (like mixing Chinese words into English answers, which Terminus was designed to fix). In fact, community evaluators report that V3.2-Exp’s outputs are consistently coherent in the target language. One German tech blogger tested it for multilingual Q&A and wrote “DeepSeek V3.2-Exp ist explizit experimentell, aber seine Antworten wirken flüssiger und stilistisch natürlicher als erwartet” — praising the model’s fluency and human-like style in German responses. This aligns with DeepSeek’s claim that V3.2 was fine-tuned to reduce “language mixing errors”, delivering clean output in the desired language.
Another category where V3.2-Exp competes is domain-specific knowledge. For instance, in the GPQA-Diamond benchmark (graduate-level physics questions), V3.2-Exp scored about 79.9, virtually the same as V3.1’s 80.7. That’s an impressive level of physics expertise for a general model. Alibaba’s Qwen-3-Max was reported to achieve ~81.4 on a similar “SuperGPQA” test, indicating V3.2-Exp is within a few points of the top score here as well. On the flip side, one area of slight dip was “Humanity’s Last Exam” — a collection of tricky analytical questions — where V3.2-Exp scored 19.8 vs. 21.7 for V3.1. Mehul Gupta, an independent AI researcher, flagged this ~2 point drop as potentially meaningful, speculating it might result from the sparsity mask occasionally missing a needed “global” connection on certain hard questions. Still, the difference is small, and others have noted it could be within normal evaluation variance. By and large, V3.2-Exp’s knowledge and reasoning capabilities remain first-rate, proving that DeepSeek’s efficiency improvements did not come at the cost of making the model “dumber” in any way. If anything, some benchmarks ticked up slightly — V3.2 even gained +0.9 on the AIME 2025 set and +75 points on a Codeforces coding challenge relative to Terminus These gains hint that the consolidated RL fine-tuning approach (merging reasoning, tool-use, and alignment training) may have given V3.2-Exp a more balanced skillset.
Reactions: What Users and Critics Are Saying
DeepSeek V3.2-Exp’s launch made waves in the AI community — and the feedback so far is a mix of excitement at its cost-efficiency and admiration for its technical nuance, tempered by a few notes of caution. User communities on Reddit and local LLM forums were quick to test the model. Many praised the dramatic price drop: “Pricing is much lower now: $0.28/M input… was $0.56 before” one user highlighted, to which another replied, “yet performance is very similar across the board”, clearly impressed that quality held steady. This sentiment — half the cost for the same results — is seen as a big win, especially for independent developers or startups for whom API costs add up. Several developers immediately integrated V3.2-Exp via OpenRouter and reported that “latency is low and throughput high”, crediting the new sparse kernels and the model’s Groq server optimizations for production-scale speed.
On the technical side, experts have lauded DeepSeek for the transparency and openness of this release. The company not only open-sourced the weights on day one, but also provided extensive tooling: from TileLang kernels for readability to FlashMLA CUDA kernels for maximum speed. The inclusion of vLLM and SGLang support on launch — frameworks that enable efficient serving of the model — was highlighted in VentureBeat’s coverage as a sign that DeepSeek is “cultivating broad community integration rather than locking down distribution”. Researchers appreciated the gesture: one described V3.2-Exp as “a controlled experiment release — the kind we need more of in AI”, referring to the way DeepSeek swapped one architectural component (attention) and held everything else constant. This clarity allows the research community to truly study the impact of sparsity on large-scale training, using V3.2-Exp as a testbed.
Independent benchmarkers like the Vals team have yet to publish a full evaluation of V3.2-Exp (their last DeepSeek entry was V3.1), but early indications are promising. Internal logs from Vals (leaked on Reddit) suggest they ran V3.2-Exp through some long-context tasks and found “with reasoning off, 3.2’s context handling is weak, but degradation over long context is low”. In other words, if you use it in default “fast” mode, it may struggle to fully utilize ultra-long inputs (a known issue in earlier V3 models), but it doesn’t dramatically worsen as the input grows — an encouraging sign for DSA’s effectiveness. Enabling the reasoning mode likely helps it actively recall distant context better, at some latency cost. This is consistent with user reports that V3.2-Exp in “deepseek-reasoner” mode can solve very long tasks step-by-step, whereas the “deepseek-chat” mode sometimes glosses over details unless prompted carefully. The two-mode approach (non-thinking vs thinking) is something DeepSeek carried over from previous versions, and it continues to offer flexibility: developers can choose speed or rigor. As one fan put it, “V3.2 is exactly the mid-step I like to see: clear wins in efficiency with only minimal dents in a few tasks”.
Not all commentary is rosy, however. Some AI practitioners pointed out V3.2-Exp is still an experimental interim model. A VentureBeat analysis cautioned enterprises to consider data governance if using DeepSeek’s API, since the company is based in Hong Kong (which might raise compliance flags in certain jurisdictions). They suggested that highly sensitive applications might opt to self-host the open-source model weights to mitigate any privacy concerns. On performance, critics note that V3.2-Exp did not markedly advance state-of-the-art accuracy — it roughly maintained it. For example, while OpenAI’s GPT-5 series and Anthropic’s Claude 4.5 have pushed some benchmarks even higher in late 2025, DeepSeek chose to prioritize efficiency for now. Some heavy users of V3.1-Terminus were initially underwhelmed that quality wasn’t significantly improved: “If V3.2 is advertised to be not much worse [than V3.1], I’m not holding my breath [for better results],” one Redditor quipped before launch. That said, these same users have come around after testing it: they found the output “feels just as good” and are now mainly interested in how sparse attention might enable new use cases like processing enormous documents cheaply, rather than in raw benchmark gains.
The Chinese AI community has been closely watching DeepSeek’s moves. Zhipu’s GLM-4.6 release came just days after V3.2-Exp, and some Chinese commentators explicitly compared them: one CSDN blogger ran both on various tasks and concluded GLM-4.6 has more human-like writing and slightly stronger comprehensive ability, but he praised DeepSeek V3.2 for extreme sparsity technique impressive and noting that its “inference cost has dropped a lot” for only very minor quality trade-offs. He did observe one quirk: when he enabled a “deep thinking” mode on GLM-4.6, it tended to overthink and mix languages in its chain-of-thought, whereas DeepSeek V3.2 (presumably in reasoner mode) didn’t suffer such issues. This indicates V3.2-Exp’s single-stage RL training might have balanced reasoning and coherence better than some competitors that bolt reasoning on top. Overall, the sentiment is that DeepSeek V3.2-Exp set a benchmark for open models in 2025: it’s highly capable, extremely cost-effective, and openly available — checking all the boxes that matter for wider AI adoption.
With V3.2-Exp, DeepSeek has delivered an uncommon thing in the AI race: a meaningful architectural innovation paired with immediate real-world benefits. This model is not just a paper experiment; it’s a deployed service, a downloadable weight file, and a step toward the future all at once. By proving that sparse attention can maintain accuracy at scale, DeepSeek has likely influenced the design of upcoming flagship models (including its own future V4). The community now has evidence that one can train a nearly 700B-parameter transformer with fine-grained sparsity and get “free” speedups — a big deal for those looking to push context lengths to a million tokens and beyond. As AI researcher Greg Robinson noted, V3.2-Exp “pushes the boundaries of what a pragmatic engineering achievement can be… it’s not just about a benchmark number, it’s about making the model actually usable at scale”.
DeepSeek has hinted that V3.2-Exp is an “intermediate step” on the road to a more radical architecture, possibly their V3.3 or V4 series. If the sparse attention experiment had failed badly, we might have seen a retreat to dense methods — but instead it appears to be a success, albeit with room to refine (e.g. mask design to avoid rare regressions like on HMMT math). We can likely expect future DeepSeek models to double down on this approach: maybe hybrid sparse–dense attention or smarter learned sparsity to further close the gap with an all-attention model on the trickiest tasks. And given DeepSeek’s open ethos, there’s little doubt they will open-source those models too, continuing to bolster the open AI ecosystem.
For now, V3.2-Exp stands as one of 2025’s most impressive open LLMs. It offers nearly the reasoning power of DeepSeek’s R1 series with the speed and versatility of the V3 line — a combination that makes it a compelling choice for a wide range of applications, from writing assistants and customer chatbots to code analysis tools and research agents. Its emergence also tightens the competition with other open heavyweights. Models like Kimi K2 and Qwen-3-Max have to measure themselves not just on raw scores but on efficiency and cost now — areas where DeepSeek just raised the bar. And even the major proprietary players must take note when an open model can match 85–90% of their quality at a fraction of the price (or free, if self-hosted). In the words of Carl Franzen at VentureBeat, “V3.2-Exp shows how an open-source player can push frontier-scale models while addressing practical challenges of cost and deployment”. It’s a reminder that innovation in AI isn’t solely about giant leaps in IQ — sometimes it’s about making our smartest models more accessible, efficient, and ready for the real world.
Learn more about DeepSeek V3.2-Exp Review. DeepSeek’s latest experimental model…