A python tutorial on L2 order book data
Introduction
As I wrote some articles covering order book trading and market making topics, some of you reached out to me and asked for a free and reliable data source for historical order book data. This type of data is typically quite expensive, so this is not an easy question to answer.
Moreover, to do some serious research, one needs at least L2 order book data, that lists prices and volumes for different depths. Long story short, you can find the free historical datasets repository of ByBit here, for L2 order book data. This data is updated daily.
In this article I will show you how to download order book historical data for free. Moreover I will run over the files documentation and propose you some code to read and format the dataset.
Download data
As you can see in the image below, ByBit provides you with free historical datasets for Spot and Contract. This is all without registration! What a wonderful resource for us!

To filter the order book dataset you can click on OB Data:

And then, hovering the mouse over the OrderBook title, click the Contract button:

Now you can choose up to 5 pairs to download (I chose BTCUSDT) and the date range (I chose from 2024–09–02 to 2024–09–03):

Then you can click on Confirm and then, in the following page, Download:

This will result in the following files being downloaded:
2024–09–03_BTCUSDT_ob500.data.zip
2024–09–02_BTCUSDT_ob500.data.zip
What’s inside the files?
Extracting one of the files from the zip archive and opening it in notepad, it will show an interesting form. It is a sequence of JSON strings, each with the following form (notice that here I reduced the length of “b” and “a” lists for illustrative purposes, they are much longer!):
{
"topic": "orderbook.500.BTCUSDT",
"type": "snapshot",
"ts": 1725321601755,
"data": {
"s": "BTCUSDT",
"b": [
[
"59116.70",
"9.490"
],
[
"59116.50",
"0.017"
]
],
"a": [
[
"59116.80",
"6.618"
],
[
"59117.10",
"0.001"
]
],
"u": 28259371,
"seq": 231805146756
},
"cts": 1725321601749
}
From the documentation, we can decode the relevant fields:
- ts: the timestamp in which the system generated the data, in milliseconds. The system captures a new snapshot of the order book every 10 milliseconds.
- s: symbol name.
- a (Asks): list containing the asks, sorted by price in ascending order. Each ask is a list, the first element is the price level and the second is the volume.
- b (Bids): list containing the bids sorted by price in descending order. Each bid is a list, the first element is the price level and the second is the volume.
Format the file into a workable dataset
In order to process the file, I will change its extension to .txt instead of .data . I will work with the file named 2024–09–03_BTCUSDT_ob500.
You can find the full code to process the dataset here.
Let me spend some words on the two main functions that compose the script: read_data and build_order_flow_dataframe:
- The first function reads the .txt file line by line, where each line corresponds to a unique timestamp. For each timestamp, the function updates two separate dictionaries: one for bid data and one for ask data. In both dictionaries, the keys are the timestamps, and the values are lists containing the price and volume data for each timestamp.
- the second function reads these dictionaries with Pandas and creates a DataFrame indexed by time (the timestamp), side (bid or ask) and level (0 is the first available price, 1 is the second, etc…), where the columns are the price and the volume.
def read_data(flow_file):
dict_a = {} # dictionary with ask data
dict_b = {} # dictionary with bid data
# read row by row the txt file
with open(flow_file, 'r') as file:
for n in tqdm(range(rows_to_process)):
riga = file.readline()
riga = riga.strip().strip("'")
obj = json.loads(riga) # it's a json object
# get the data
ts = obj['ts']
a = obj['data']['a']
b = obj['data']['b']
# if data is empty continue
if (not a) or (not b):
continue
# populate the dictionaries
dict_a[ts] = a[:max_depth]
dict_b[ts] = b[:max_depth]
return dict_a, dict_b
def build_order_flow_dataframe(dict_a, dict_b):
def format_df(dictionary):
# build a dataframe from dictionary
df = pd.DataFrame(pd.DataFrame().from_dict(dictionary, orient='index').stack())
df = pd.DataFrame(df[0].tolist(), index=df.index)
df = df.rename(columns={0: 'price', 1: 'volume'})
return df
ask_df = format_df(dict_a)
ask_df['side'] = 'ask'
bid_df = format_df(dict_b)
bid_df['side'] = 'bid'
flow_df = pd.concat([ask_df, bid_df])
flow_df = flow_df.reset_index()
flow_df['level_0'] = pd.to_datetime(flow_df['level_0'], unit='ms')
flow_df = flow_df.rename(columns={'level_0': 'time', 'level_1': 'level'})
flow_df = flow_df.set_index(['time', 'side', 'level'])
flow_df = flow_df.sort_index()
flow_df['price'] = flow_df['price'].astype(float)
flow_df['volume'] = flow_df['volume'].astype(float)
return flow_df
Here you can find the first rows of the resulting DataFrame:

Now the dataset is ready to be used for any research purposes! 🐦
Bonus section: visualization
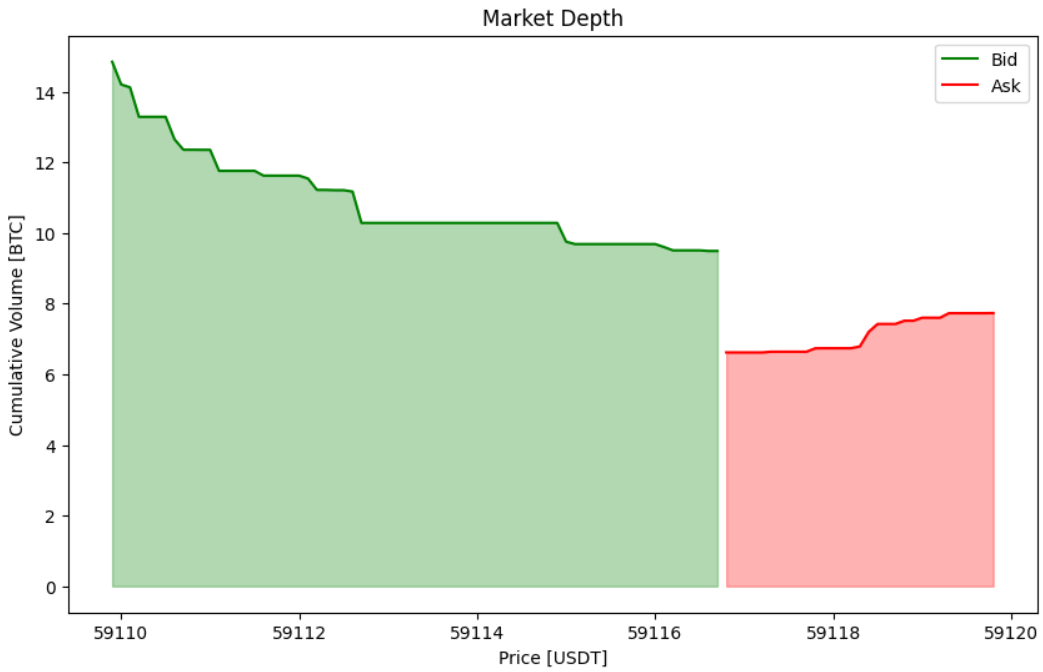
As a bonus, I added the plot_order_book function, that allows to visualize what we just downloaded. This is just the common depth representation of the order book.
As you can notice, these data is quite interesting, since we see that the bid depth is much greater than the ask, the bid-ask spread is small and the price levels for the bid are sparse (a flat line in the cumulative volume plot means that no volumes are present in those price levels!).

Conclusion
As you might have noticed, there are a lot of datasets in the ByBit historical repository, for example the tick-by-tick transaction dataset, something that I might cover in future articles.
Given that you now have some real L2 order book data, you might want to build some solid foundation on order book models. You might be interested in some of my previous articles on the theme, like:
- Sequential Trade Model for Asymmetrical Information
- Distribution of the Order Flow in Python
- Using the Order Book depth to unveil informed trading
Now it is your turn!
You can start playing with these historical data and try to find some patterns. Let me know if you find something interesting!
Learn more How to download and format free historical order book dataset