Note: this post is part of a series of posts regarding HP3804 (Psychological Testing)
Factor Analysis is a methodology to determine the factor structure of the scale. A factor structure comprises of 2 things mainly:
- The number of factors that a scale is measuring.
- Which items load onto which factor
So a factor structure (end product of factor analysis) can look something like this:

Factors, in this context, are by definition the unidimensional constructs we learnt about previously (please revise the terminology if this is unfamiliar to you!)
Types of Factor Analysis
Broadly speaking — there are 2 “types” of factor analysis:
- Exploratory Factor Analysis (EFA)
- Confirmatory Factor Analysis (CFA)
This distinction is somewhat “wrong” though — because these two types are actually based on the same methodology (the correlation between items in the scale). We split factor analysis into these two types because they are used for different reasons — exploratory factor analysis is used to explore the factor structure of a scale, whereas confirmatory factor analysis is used to prove the factor structure of a scale.
Which is why — as the names suggest — exploratory factor analysis is often used in the exploratory phase of scale development, whereas confirmatory factor analysis is used in the later stage to confirm a proposed factor structure.
In reality, scale development is often done using a semi-confirmatory approach — blending both exploratory and confirmatory factor analysis. In my group project for instance, our hypothesised factor structure showed extremely poor fit using confirmatory factor analysis — hence we had to revert to exploratory factor analysis in the end. Point being, don’t think of these two methods are mutually exclusive from either other. Instead, think of them as 2 ends of a spectrum — differing in terms of how much pre-conceived knowledge you have about your model.

How does Factor Analysis Work?
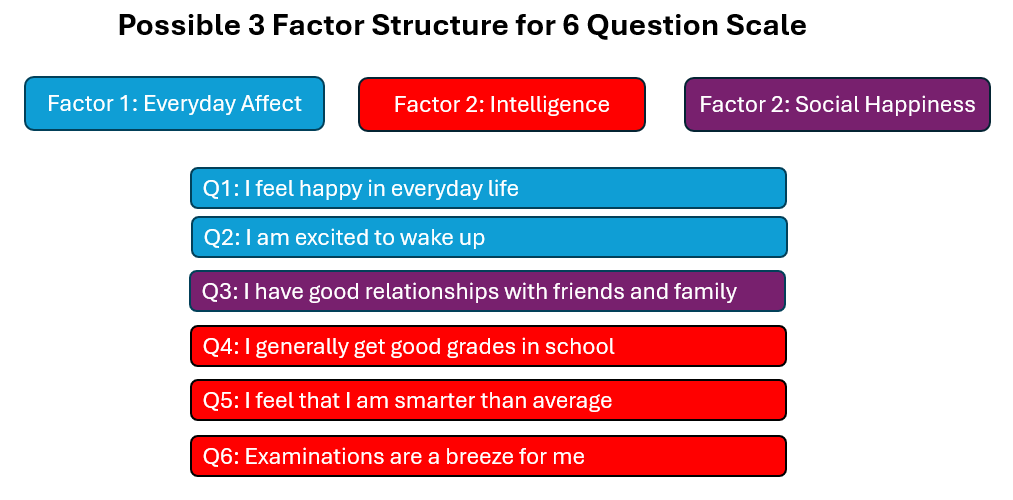
Let’s start slow so that you get the intuition of factor analysis right first. Say you are given a scale which you have no information about. The scale comprises these 6 questions.

Just by reading these questions — you can broadly classify the questions into 2 groups — whereby you expect the items within each group to have highly correlated scores with each other becausethey are measuring the same construct (items in different groups are expexted to have low correlation with each other, becasue they are measuring different constructs)

Or perhaps, you may disagree with me and feel that this scale should have this factor structure instead:

And that’s the point! Based on reading the questions alone — there can be multiple interpretations of which items belong to which factor — and how many factors the scale is measuring in the first place. Factor analysis helps us find the “best” factor structure for the scale based on (several) quantitative metrics. Which is what makes it such a powerful tool!
Fun Facts about Factor Analysis
Factor Analysis is one of the few statistical method whose origins lie in Psychology! Statistics is applicable everywhere in life — for instance Split Plot Designs that we learnt in HP3101 had its roots in agriculture. The original creator a factor analysis was Spearman (the intelligence guy) — but I think the most notable applicable of it comes from the OCEAN model of personality (or maybe just because HP2500 Personality Psych is fresher in our minds at this point lol).
Remember your lexical hypothesis? Indeed — you can imagine that all the words used to describe personality in dictionary are asked in this manner:
Describe the extent to which you are ______ on a scale of 1–10.
Repeat this question for all words in the dictionary, then do factor analysis on them — and theoretically you should be above to derive the OCEAN model yourself!
Factor Analysis Basics — Conceptual Understanding & Terminology
With all that said — it’s important to go back to basics and emphasize on some crucial points about Factor Analysis. Factor Analysis is a clustering/dimension reduction tool — it is used to find a few underlying dimensions from numerous item level questions.
The entire premise of factor analysis is that several questions in the scale are measuring a single underlying unobserved (latent) factor. The model looks something like that:

We make a distinguishment between observed and latent (unobserved) variables — observed variables are things you actually have data on (e.g. participant responses to a question), whereas latent variables are things you don;t have direct information on (and hence must infer from the observed data).
Keep this knowledge in mind — we will have to use it a lot for factor analysis, especially when we get to Confirmatory Factor Analysis. Confirmatory Factor Analysis can be viewed as a special case of the broader technique of Structural Equation Modelling (SEM). If you took HP4012 before HP3804, CFA will be easy for you. I took it the other way around though, so I learnt the narrower technique (CFA) before SEM. Either way is fine.
Why do Dimension Reduction/Clustering?
To be frank — the Psychology-specific reason for clustering is quite different from the general reason why we do clustering in the broader world of data. In Psychology, we often do clustering of items for scale development purposes. We want to prove that certain questions in the scale measure one, and only one construct, while others measure another construct. (think about how a personality questions tends to have questions measuring both extroverion and agreeableness, and how these questions generally tend to be distinct).
Elsewhere, we do clustering to simplify the data — to group participants/objects so that they are easier to understand (as a group instead of individuals). This makes analysis easier — as instead of dealing with a dataset comprising of 1000 individuals, I can analyse 3 clusters of people — making things a lot more manageable.
Both “types” of clustering still involve the same underlying principle of grouping — though the end product feels rather different. Understanding these nuances will help you a lot as you go on to learn about more true blue clustering techniques in the future, such as hierarchical clustering, k-means clustering, or what not.
Conclusion
I think that’s enough for an introduction to factor analysis! Talking more about it at this point will feel very airy to you anyways — it’s time to give you something concrete you can actually work with.
In our next post, we’ll be doing just that: Exploratory Factor Analysis with a questionnaire that we don’t know anything about!
Learn more about HP3804 NTU Psychology Statistics: Module Review (Introduction to Factor Analysis)