Note: this post is part of a series of posts regarding HP3804 (Psychological Testing)
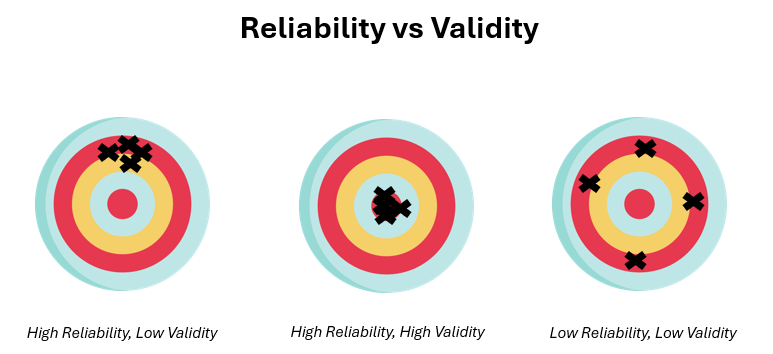
With Reliability covered — we can now move on to Validity (also known as accuracy). I’m sure you have seen this picture before illustrating the difference between Relaibility and Validity:

The above archery picture is something you would likely have seen back in secondary school — when your physics teachers were trying to explain to you the difference between reliability and validity (throwback to Vernier Caliper Days!)
Here’s somthing the probably didn’t tell you however — reliability precedes accuracy (validity).
Why, you may ask? I don’t know if you guys have ever played archery before — or for the Singaporean Guys when you did your live firing during NS, you would have realised that your instructors cannot advice you on anything other than “try to shoot more consistently” if your shooting is all over the place.
Because it’s simple, really. You cannot be accurate if you are not consistent. Consider the below scenario:

Accurate? Perhaps? (some did hit the bullseye). Reliable? Definitely not.
Point being, you need ensure that you are actually measuring something (reliability) — before you can ask what it is measuring (validity). If you can’t consistently measure one thing, there’s really no point talking about validity at all because even if you do the bullseye occasionally — people won’t trust your skills because it may be a fluke. Measurements scales follow the same concept!
Which is why validity only comes into play when your measurement is reliable. Only when you know you are consistently hitting one specific area — then you can go and ask — am I hitting the bullseye that I want to hit?
Validity Explained
With all that said — what exactly is Validity, and how do we define it? Validity describes the extent to which you are measuring what you want to measure (bullseye). To give a more concrete example, say I have a question of “I am generally a happy person”. This question is part of an extroversion scale. Do you think it is a valid question?
Yes… and no? Research does indeed suggest that extroverts tend to be happier than introverts on average — so there is some basis to this question being a valid measurement of extroversion. But is it all? Definitely not.
Which brings me to the first type of validity I want to introduce to you — Content Validity.
Content Validity — One Form of Validity
Content Validity describes the extent to which your measurement scale covers all aspects of your construct. For extroversion, it would include things like happiness, energy around people, enjoyment of meeting strangers etc etc. My single question of “I am generally a happy person” is definitely insufficient to cover all aspects of extroversion — making it weak in terms of content validity. Do note that validity, similar to reliability, is judged at the scale level— not at the item level. So a more accurate (hah!) depiction of low content validity would be if all questions in the extroversion scale revolve around happiness only.
People argue that their scale has high content validity — in a similar manner to how I did above. Unfortunately, there’s no quantitative metric for content validity — only qualitative arguments. So to “prove” content validity, typically we need to go interview subject matter experts, do literature review, find past scales that measure similar things for comparison — etc etc etc. (this links back to why HP3804 has the strongest qualitative component out of all the statistics modules in NTU — scale development has an inherent qualitative component to it! You can’t run away from arguments in the field of psychometrics unforatey. Say bye bye to your simplistic decision rules of p < 0.05!)
If there’s no quantitative metric for content validity — is thre a quantitative metric for other forms of validity? Yes, there is!
Convergent & Divergent Validity
Convergent/divergent validity are one of the most commonly reported forms of validity — simply because it’s easier to show a number than read an entire essay about why the scale is valid. Convergent/divergent validity is defined as the correlation (back to basics folks!) between your scale score and other similar/dissimilar scale scores.
To illustrate this, say I am developing a new scale to measure extroversion (lol I am milking this construct). I expect the my new scale score to be moderately correlated with happiness scales — because happiness is a component of extroversion (as much as the introvert in me disagrees personally with this, in the literature this is accepted so…. oh wellz.)
On the other hand, I would expect my scale to have no to low correlation with an unrelated scale — say foot size. If there is a correlation betwee foot size and extroversion… well… Something is wrong.
To display convergent/divergent validity, we sometimes show a congergent/divergent validity table like this:

Importantly, the values in green showcase should show the moderately high correlations with related constructs, while the values in red should show a low correlation with unrelated constructs.
Side note 1: For convergent validity — it is important to remember that you want moderately high correlation — not super high correlations! Rationale is because if the correlation is too high — your scale is not measuring anything new — and there’s no point using your new scale (I can just use the old one!)
Side note 2: No correlation does not mean negative correlation okay! In psychometrics the direction of things does not typically matter as much — we just flip the sign to align the direction. Say I am correlating an introversion scale to an extroversion scale — obviously the scale scores are going to be strongly, negatively correlated (say r = -0.9). This is still under CONVERGENT validity — not divergent! Because constructs are stll stronlgy related!
Side note 3: I have always found the concept of divergent validity a little weird though. I mean, you can theorectically pick any unrelated construct in the WORLD to get the low correlation (idk, average urine output per day?) So I don’t really see the point in it. Unless, it is to be used when you want to prove that your new scale is different from an existing construct — but even under this scenario it would fall under the moderately correlated (convergent validity) because you have this scenario when the existing scale is similar to your new scale in the first place. So I can’t think of any real scenario when divergent validity is truly useful — do correct me if I’m wrong though.
How Reliability Affects Validity — Correction for Attentuation
One last thing before I wrap this up! Validity coefficeints are correlation coefficients — you are using the scale scores to perform correlation. But we know that scale scores by themselves are not 100% reliability— because any measurement will naturally have error. Your validity correlation — being based on this measurement — will natrually be smaller than the “actual” because of the error in the measurement (the relationship is diluted becauser of random error in both scales).
Which is why we do Correction for Attentuation — which gives you the validity coefficient if you had perfect reliability for both measurements. The formula is as follows:

Of course — you can choose if there are certain measurements that you want to assume perfect reliability — you need not assume that both measurements are imperfect. This is especially common if you are measuring criterion validity (often a more concrete, real world behaviorual outcome in contrast to convergent validity).
Say your scale measures intelligence and your criterion is a student’s GPA. Naturally, with just that 1 datapoint for GPA as the criterion variable, reliability cannot be estimated (and usually assumed to be perfect since… well… there’s unlikely to to any “error” in it). So just substitute r = 1 for your yy variable in the formula above — which essetially “removes it” — and the true validity will be adjusted only for unreliability in the xx variable alone. Cool right!
Conclusion
So we now understand both reliability and validity. Give yourself a pat on the back!
Reliability and Validity should only be used when interpreting unidimensional constructs. But how do we know whether a construct is unidimensional or not? Yes, we can always do qualitative arguments (lame) that our scale questions all revolve around 1 particular construct — but is there any empirical way to prove unidimensionality?
The stage is set for us to move into the crux of the HP3804 module — Factor Analysis. Let’s go! Exciting times ahead!
Side note: Hehe, sorry, I am totally a quantitative person. No offense to the quali folks, though — it has its own uses. My ‘lame’ is more of a joke than undermining the value of quali. But I’m guessing if you’re a quali person, you’re probably not reading this post anyway (oops).
References
<a href=”https://www.flaticon.com/free-icons/target” title=”target icons”>Target icons created by Freepik — Flaticon</a>
Learn more about HP3804 NTU Psychology Statistics: Module Review (Validity of a Scale)