Modern AI systems power everything from search engines to recommendation feeds. Yet when I moved from academic research to building production machine learning systems, I discovered a humbling truth: models that looked flawless on benchmark datasets often stumbled when faced with real users. Human-in-the-loop (HITL) evaluation became my bridge between theory and practice, a way to integrate human expertise directly into model evaluation and catch failures that automated metrics miss entirely.
In this blog, I’ll share what I’ve learned working in both worlds. We’ll explore what HITL evaluation means beyond textbook definitions, why it has become essential for building trust in production AI, and how combining expert human review with automated metrics reveals insights neither can provide alone.
Based on what I’ve learned from research and real-world work scaling recommendation systems, I’ll focus on what works in practice: designing useful rubrics, building labeling workflows that scale, finding consensus methods that balance cost and quality, and applying active learning strategies that hold up in production.
The goal is to give AI and ML engineers a structured, technical, and engaging guide to deploying HITL evaluation for more reliable and user-aligned AI systems.
What is human-in-the-loop (HITL) evaluation?
Early in my industry career, I deployed a recommendation model that crushed our offline metrics: precision up, recall up, every benchmark green. Two weeks after launch, user satisfaction dropped. The model had learned to exploit patterns in historical data that predicted clicks but produced repetitive, frustrating content. Our automated metrics could not see what was obvious to any human: the system was gaming itself, not serving users.
That failure taught me why human-in-the-Loop (HITL) evaluation, which incorporates human judgment at critical stages rather than relying solely on automated metrics, is not optional. In academic papers, HITL appears as a nice-to-have. In production, I’ve learned it is essential.
While transitioning from research to industry, I noticed a pattern: the models that succeeded were not always the ones with the best offline scores. They were the ones where someone with domain knowledge looked at outputs and asked: Does this make sense? That human gut check catches what algorithms miss — nuance, context, fairness, and subtle quality issues invisible to precision-recall curves.
Automated metrics confidently overlook bias in edge cases, cultural context, sarcasm, and outputs that technically fit training distributions but violate common sense. Human evaluators reveal the unknown unknowns your metrics were never designed to measure. This oversight is legally required in regulated domains I’ve worked in, such as healthcare, finance, and content moderation. But even in lower-stakes applications, I’ve found that human evaluation costs less than deploying models that erode user trust.
The best evaluation pipelines I’ve built combine both approaches strategically: They use machine speed to filter what matters, then apply human expertise where it counts. That balance — efficient quality control that keeps models reliable and aligned with what humans need — is what HITL evaluation is about.
Automated metrics vs. human evaluation
When evaluating an AI model, we typically have two broad approaches: automated metrics and human judgment. Each has distinct strengths and weaknesses:
- Automated metrics (Offline evaluation): Automated metrics are quantitative measures like accuracy, F1 Score, BLEU/ROUGE (for language models), or precision@K and RMSE (for recommenders). They compare model outputs to references or logged data, offering fast, objective, and scalable benchmarks for well-defined tasks. However, these scores often correlate poorly with human judgment on complex or subjective outputs. Metrics can overlook qualities users care about, such as relevance, novelty, or tone, and may mislead if based on biased or outdated data. In recommendation systems, especially, strong offline metrics don’t always translate to real user satisfaction. In short, metrics are essential for benchmarking but insufficient for measuring real-world performance.
- Human evaluation (expert or user review): Human evaluation involves people assessing model outputs based on criteria, rating single outputs (pointwise) or comparing two (side-by-side). It’s the gold standard for subjective quality, assessing nuance and context across all modalities (text, image, video, audio). However, it’s time-consuming, costly, and has variability/subjectivity. Finding qualified experts for specialized domains can also be challenging. While offering rich, reliable insights, it demands significant resources, time, and careful quality control.
Bridging the gap: Combining metrics with human judgment
Rather than choosing one approach over the other, state-of-the-art evaluation combines automated metrics with human insight to get the best of both worlds. Automated metrics can provide broad coverage and quick feedback, while human evaluation can drill into qualitative aspects and validate whether high metric scores mean real-world quality. By using them together, we can often identify issues that would be invisible if only one method were used.
One way to blend the two is through human-in-the-loop workflows, where metrics are used as a first pass, and humans focus on cases where metrics are insufficient or unclear. For example, a team might use an automatic metric to filter out the worst-performing model variants, then human experts deeply evaluate the top few models to pick the best one. Alternatively, humans might label a sample of outputs for qualities like relevance or bias, and those labels then serve to calibrate or train automated evaluators. In fact, research has shown that when you align an automated evaluation (like an AI-based judge model) with human criteria, you can dramatically speed up ongoing evaluations without losing the fidelity of expert judgment. An example of this rubric-guided approach: The research reported building a system where an LLM first scores outputs against a set of criteria, and those LLM scores are then validated or adjusted by human experts, thus ensuring the automated judgments stay aligned with human standards. This kind of human-guided automation can yield a final evaluation that is both scalable and trustworthy.
Another benefit of combining approaches is improved insight and debugging. Automated metrics might tell you what is happening (e.g., Model A’s precision is 5 percent higher than Model B), while human evaluations can tell you why and how it matters (Model A’s recommendations feel more personalized and diverse to users). Together, they allow engineers to iterate intelligently: metrics for broad signal, humans for deep understanding. A striking example comes from recommender systems: academic and industry experience shows that pure algorithmic rankings often do not correlate with actual human preferences in practice. By incorporating real human feedback on recommended lists, teams can discover discrepancies (like recommendations that technically fit historical data but make no sense to users) and fix them.

To summarize, automated metrics vs. human evaluation is not an either/or choice. The most robust evaluation pipelines use metrics for what metrics do best (speed, objectivity on clear-cut criteria) and use humans where they are irreplaceable (nuance, value judgments, catching the unknown unknowns). Combining both yields a more comprehensive evaluation of model performance than either alone.
Case studies: HITL evaluation in recommendation systems and AI workflows
Real-world AI leaders have embraced human-in-the-loop evaluation to improve their systems. Let’s look at a few illustrative case studies, especially in recommendation systems, where trust and relevance are paramount:
- YouTube (Human feedback for quality and satisfaction): YouTube’s recommendation algorithm is famously driven by user engagement metrics like clicks and watch time. However, YouTube discovered early on that optimizing purely for clicks led to poor outcomes (users would click but not actually watch). They introduced watch time as a metric in 2012 to prioritize videos that people spend time on. Yet, even watch time wasn’t enough, as people might watch content they later regret. So YouTube went a step further: they added user satisfaction surveys into the evaluation loop. After watching a video, some users are asked to rate it (1 to 5 stars) and explain why they liked or disliked it. Using these human-provided ratings, YouTube defined a new metric called valued watch time, i.e., time spent on videos that users personally rate as valuable. Only videos rated highly (4 or 5 stars) count as truly positive watch time. Not everyone answers surveys, so YouTube trains ML models to predict user survey scores for videos at scale. They even hold some survey data to verify that the model’s predictions align with human feedback. This is a powerful example of combining automated prediction with human-in-the-loop data. The result is a system that tries to maximize time well spent rather than just time spent.
Additionally, YouTube employs expert human evaluators to ensure recommendation quality for sensitive content. For example, they have certified evaluators (with detailed guidelines) to rate the authoritativeness of news or science videos and identify borderline content (misinformation, etc.). Videos deemed low-quality or borderline by humans get demoted in recommendations. These human judgments are used to train a model that scales to all videos on the platform. By doing this, YouTube can promote reliable content and reduce the spread of harmful content via recommendations, aligning the system with societal trust expectations.

- Netflix beyond RMSE (Aligning metrics with user experience): Netflix provides another illuminating case. Back in 2009, Netflix famously ran the Netflix Prize competition to improve its rating prediction algorithm; the winning solution optimized the RMSE (root mean squared error) of predicted user ratings by 10 percent. Yet Netflix never fully deployed that winning algorithm. Why? Offline, the metric looked better, but the improvement didn’t translate into a noticeably better product. The engineering complexity was high; meanwhile, Netflix’s business had evolved. In a 2012 blog, Netflix admitted that additional accuracy gains in prediction did not seem to justify the engineering effort for production. This taught the industry a valuable lesson: optimizing a narrow metric can lead you astray if that metric isn’t tightly coupled with genuine user satisfaction or business value. Since then, Netflix has shifted toward more holistic and human-centered evaluation of recommendations. They focus on metrics linked to long-term member satisfaction, e.g., retention, continued engagement, and content quality, rather than just short-term clicks. Netflix engineers described using proxy metrics and reward modeling to capture long-term satisfaction, essentially crafting metrics that better reflect what makes users happy in the long run. While much of Netflix’s process is proprietary, it’s known that they rely heavily on online A/B testing (i.e., showing different recommendations to random user groups and measuring real engagement) as the ultimate evaluation of a recommender change. A/B testing is a form of human-in-the-loop evaluation at scale: millions of users effectively vote with their behavior. Offline metrics are used as a gating mechanism, but true success is decided by human behavior in live experiments, which often reveals things that offline tests can’t foresee. The Netflix case underscores the need to combine offline metrics with human impact measures. It highlights the importance of aligning evaluation with what real humans value, even if that means incorporating human judgment (through test audiences, surveys, or behavioral analysis) into the evaluation pipeline.
- Spotify algotorial human (AI collaboration): Spotify’s music recommendation approach illustrates a more product-focused human-in-the-loop strategy. Spotify employs expert curators to craft certain playlists (like RapCaviar or mood-based playlists), then uses algorithms to personalize and scale them, a hybrid they call algotorial (algorithm + editorial). Why is this relevant to evaluation? Because deciding what makes a playlist good for a certain context (say, a road trip playlist full of sing-along classics) involves qualities that algorithms alone struggle to evaluate. Spotify’s editors define the playlist criteria (e.g., familiar, singable songs for a road trip) and gather candidate tracks using their domain knowledge. Some attributes, like the nostalgic sing-along quality of a song, are hard to describe in algorithms — you know it when you hear it. This is where human intuition guides the system. The editors use their understanding of music and culture to ensure the content pool meets the intended vibe and quality. They even monitor metrics on tracks’ performance in the playlist, blending data into their curation. Once the pool is set, algorithms personalize each user’s ordering and selection, and feedback (skips, saves) is fed back to improve the models. In essence, Spotify’s team has created an evaluation loop where humans evaluate and curate the content (the recommendations candidates) and algorithms evaluate user behavior to fine-tune personalization. This human-in-the-loop approach has successfully scaled expert musical judgment to millions of users. The lesson for AI evaluation is that humans best define certain experiential criteria (like musical appeal or content trendiness); the AI can then work within those human-defined parameters and optimize further. By combining expert review with algorithmic analysis, Spotify ensures its recommendations feel right to listeners.
Techniques for implementing HITL evaluation
Implementing human-in-the-loop evaluation in practice requires careful planning and the right tools. Here are some practical techniques and best practices for effectively combining expert review with metrics.
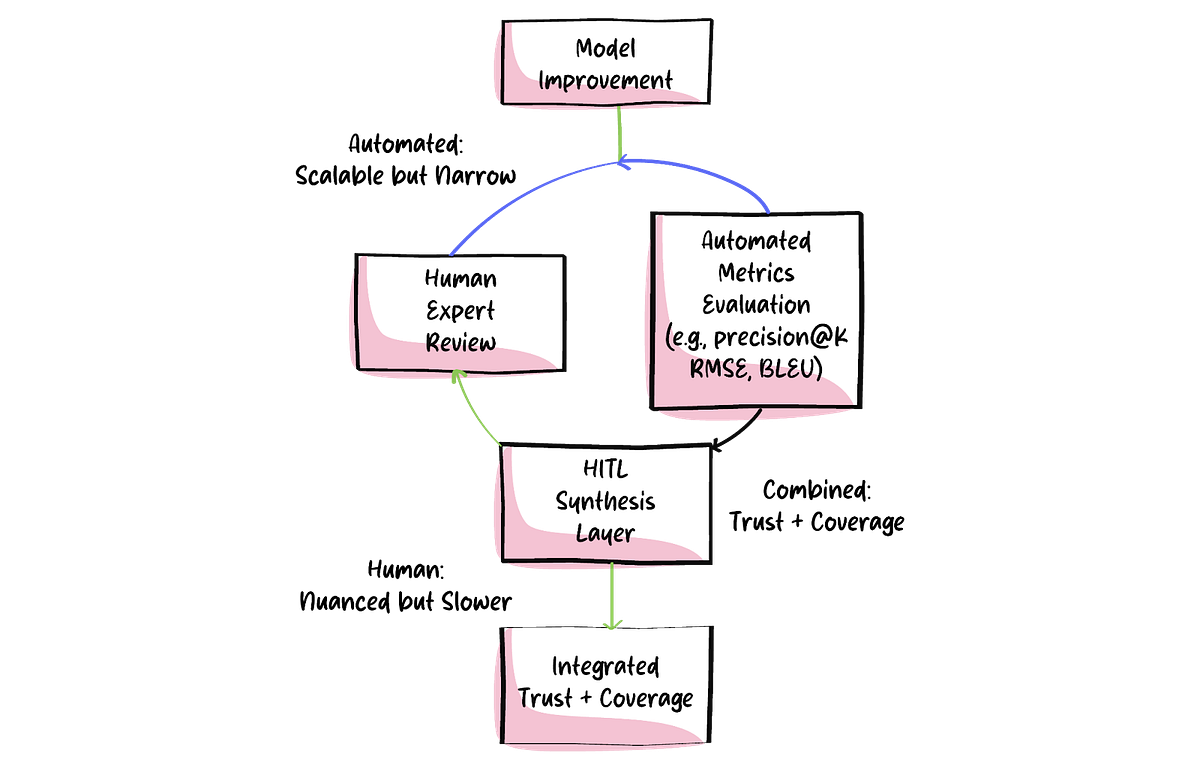
Before discussing the individual techniques, the following diagram shows how these elements fit together within a modern MLOps stack. It illustrates how automated metrics, human evaluation, and feedback loops interact to form a continuous improvement cycle.

- Define clear evaluation rubrics: Rubrics are structured guidelines that define good model outputs. They involve specific criteria (e.g., relevance, novelty) and a clear rating scale, translating abstract concepts into repeatable scores. Rubrics ensure consistent evaluation by human and automated judges, improving inter-rater agreement and providing granular feedback for model improvement. Snorkel AI highlights rubrics as reliable, nuanced, and consistent tools for evaluation. It’s recommended to involve domain experts in rubric design and refine vague criteria through piloting.
- Crowdsourced labeling and workflows: To conduct large-scale human evaluations, utilize crowdsourcing platforms (e.g., Amazon Mechanical Turk, Toloka) or internal teams. This involves distributing tasks like rating recommendations, requiring clear task design, detailed annotator instructions with rubrics, and robust quality controls. Craft a user-friendly interface, provide examples, and use pre-screening or qualification tests for annotators. Implement quality checks like gold examples or agreement checks. Many companies use custom workflows or tools for this. Treat human evaluators as a key pipeline component, providing training and feedback. Toloka, for instance, uses skilled annotators and sophisticated quality control. Begin with a small pilot, assess consistency, and then scale up. For high-stakes evaluations, leverage platform features like consensus tasks or reviewer hierarchies.
- Consensus and aggregation methods: When multiple humans are involved in evaluation, their inputs must be aggregated to mitigate individual bias. Common methods include majority voting, averaging, or advanced algorithms weighting annotator reliability (e.g., Dawid-Skene, Bradley-Terry). Open-source libraries like Crowd-Kit provide implementations. Other approaches involve identifying outlier judgments or using task-specific aggregation (e.g., 80 percent agreement for search relevance). The goal is to reduce noise and achieve stable, reliable evaluation metrics from human input. The number of annotators per item should be based on complexity; harder tasks may require 3–5 judgments, while simpler ones might need one with audits. Statistical aggregation helps derive a reliable ground truth for metrics and decision-making.
- Active learning and smart sampling: Active learning strategies can reduce the cost of human evaluation by having the model identify the most informative data points for human review. Instead of random sampling, the model flags cases where it’s least confident or where models disagree, maximizing the value of each human label. This significantly cuts labeling volume, time, and cost while improving the model. In evaluation, active learning creates a dynamic evaluation set, continuously sampling challenging cases for human review, keeping the dataset fresh and focused. While active learning optimizes model performance with fewer labels, human-in-the-Loop (HITL) ensures broader oversight and quality. Combining both is powerful, focusing human effort where most needed.
Tip: Implement uncertainty measures in your model, and periodically have humans label a batch of the top uncertain outputs. Use these judgments to update the model or adjust evaluation metrics, concentrating human effort on critical edge cases.
- Tooling and integration: Integrate human-in-the-loop (HITL) evaluation as a core part of your ML pipeline. Use tools like Snorkel Flow or Azure Human-in-the-loop, or build your own, to seamlessly incorporate human feedback. This includes dashboards for reviewers and logging systems to flag outputs for human review. Automation, such as LLMs acting as co-pilots for evaluations, can assist human reviewers. With the right tools, HITL evaluation can be efficient at scale.
Challenges and how to mitigate them
While human-in-the-loop evaluation strengthens trust and quality, it introduces practical challenges. Here are common issues and ways to manage them:
- Cost and scalability: Human evaluation is slow and expensive, but essential for trustworthy AI. Focus on critical areas, use active learning to target edge cases, and sample selectively. Combine internal experts for high-stakes reviews with crowdsourced workers for simpler tasks. Track ROI through measurable gains in accuracy or satisfaction.
- Latency and speed: Automated metrics give instant feedback; human reviews take time. Plan evaluation rounds early, maintain a ready pool of annotators, and combine both approaches. Asynchronous or overnight human checks can catch issues without delaying model iteration.
- Subjectivity and inconsistency: Clear rubrics, evaluator training, and anonymous reviews reduce variability. Use multiple annotators and consensus methods, and monitor reliability with measures like Cohen’s kappa.
- Quality control: Humans make errors, too. Apply gold-standard checks, audits, and feedback loops. Use crowdsourcing platform tools for quality control and hold calibration sessions for experts. Treat human evaluation data with the same rigor as model data.
- Integration overhead: Adding human feedback increases complexity and may face resistance. Start small and show how human review prevents costly failures. Automate where possible and focus on high-impact checkpoints like final sign-offs or bias audits. Over time, streamline the process as model reliability grows.
Deploying HITL evaluation at scale: Guidance for teams
Implementing human-in-the-loop evaluation in a real-world, large-scale pipeline requires a strategy. Here are some guiding principles and tips for teams looking to deploy HITL effectively at scale:
- Align on objectives: Clearly define the purpose of human-in-the-loop (HITL) evaluation, whether for ethical AI, subjective user experience, or critical application verification. Your goal will determine the human input needed. For instance, a team focused on fairness might review outputs for bias, while a recommendation team might assess subjective enjoyment. Ensure human evaluation criteria align with product success and values.
- Pilot and iterate: Don’t expect a perfect HITL pipeline from day one. Start with a pilot program: perhaps have a small group of domain experts review a batch of model outputs and provide feedback. Use that to refine your rubrics and processes. For instance, you might discover that reviewers needed more context to evaluate properly, or that the rubric had an unclear category. Iterate on the guidelines and task design before scaling up. Early pilots can also help estimate how long tasks take and what volume of human input is feasible, which informs how you scale.
- Use expertise wisely: Choose the right humans-in-the-loop based on your needs. This could involve domain experts (e.g., doctors for medical AI), a crowd of laypeople for general judgments (e.g., search relevance), or a mixed approach. The ideal human provides the knowledge or perspective that the AI lacks. Consider involving end-users through studies or beta tests for authentic insights.
- Integrate into the ML pipeline: Integrate human evaluation into your model’s CI/CD. When training a new model, automatically send test set outputs for human rating as a standard pre-deployment step. Establish go/no-go criteria (e.g., no critical failures, X percent improvement over the previous version). Use evaluation dashboards to display both metric and human evaluation results, making HITL a regular part of model development to ensure quality.
- Use feedback to improve models: Integrate human evaluation data to improve AI models through retraining, fine-tuning, or adjusting algorithms based on feedback. This closes the loop, ensuring human insights drive model enhancements, not just measurement.
- Measure and optimize the HITL process: Evaluate your human-in-the-loop (HITL) pipeline. Track metrics like human catch rate of critical issues, evaluation time, and cost to justify resources and streamline the process. Reduce evaluations that lack new insights and shift effective ones earlier in the pipeline if post-deployment issues are frequent. Treat HITL as an evolving system, even using A/B testing for instructions or rewards. Quantify HITL’s impact on model performance to refine human involvement for optimal outcomes.
- Gradually increase automation: As models improve, you can reduce human oversight but never eliminate it. Incrementally cut manual review once confidence is high, perhaps moving to spot-checks after consistent ≥95 percent accuracy. Define and document these thresholds. Always keep a fallback: bring humans back for out-of-distribution operation or major updates. Establish a clear conflict resolution protocol, escalating human-flagged issues to experts for final decisions and retraining data, which ensures system integrity as it scales.
In conclusion, human-in-the-loop evaluation is a powerful approach to increase the trustworthiness and quality of AI systems, especially in areas like recommendation engines, where human preferences and context are complex. By thoughtfully combining automated metrics with expert human review, teams can achieve a more holistic understanding of model performance. The process is not without challenges as it requires effort, investment, and iteration, but the payoff is AI models that are not only quantitatively sound but also qualitatively aligned with what users and society expect. As AI systems continue proliferating in critical domains, incorporating the human touch in evaluation and oversight will ensure these systems remain accountable, fair, and effective. Teams that deploy HITL at scale with solid techniques (rubrics, crowdsourcing, consensus, active learning) and a clear strategy will be well-positioned to deliver trustworthy AI that users can rely on, striking the right balance between automation and human wisdom in the loop.