This paper introduces a groundbreaking approach to addressing a critical challenge in the rapidly evolving landscape of large language models (LLMs): plagiarism. As LLMs become more sophisticated and widely adopted, the issues surrounding intellectual property, unauthorized weight reuse, and proper attribution are becoming increasingly complex and urgent.
Abstract Summary
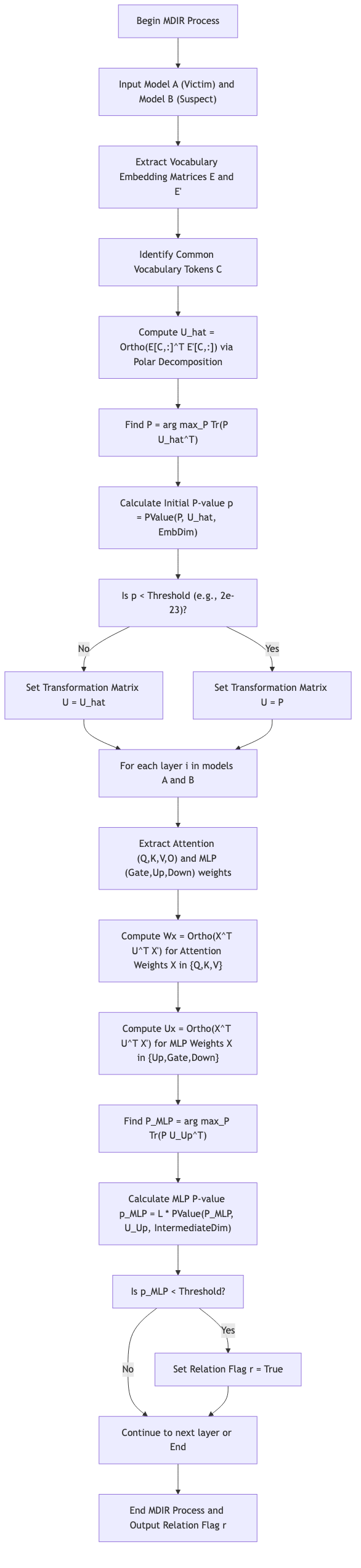
The paper tackles the growing concern of intellectual property (IP) infringement in Large Language Models (LLMs), where models might plagiarize others by direct weight copying, upcycling, pruning, or continual pretraining without proper attribution. Current detection methods often fall short; they struggle to reconstruct specific weight correspondences, lack rigorous statistical measures like p-values, and can mistakenly flag models trained on similar data as related.
To overcome these limitations, the authors propose Matrix-Driven Instant Review (MDIR). This novel method employs advanced matrix analysis, including Singular Value Decomposition (SVD) and polar decomposition, combined with Large Deviation Theory. MDIR is designed to accurately reconstruct weight relationships, provide robust p-value estimations for statistical significance, and focus exclusively on detecting…