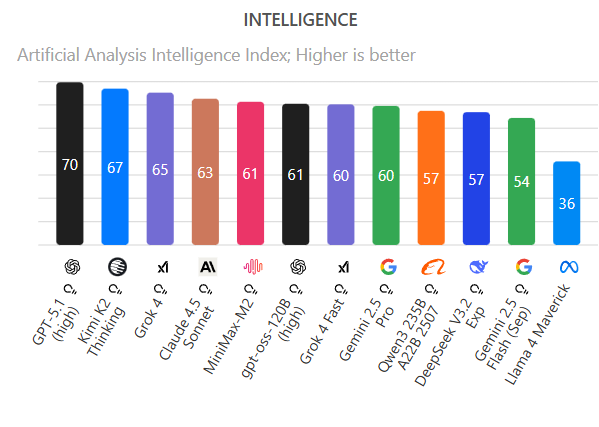
On October 23rd, 2025, a Shanghai-based startup MiniMax open-sourced MiniMax M2, a new large language model purpose-built for coding and “agentic” tasks. This model packs major capabilities – it debuted as the highest-performing open-weight AI on a broad intelligence index, closely trailing only proprietary giants like Claude Sonnet 4.5 and GPT-5. Later it was overtaken by a much larger open-weight Kimi K2 Thinking and GLM-4.6 models. MiniMax M2 was designed to excel in real-world developer workflows (like writing and fixing code, using tools, and web browsing) while operating at a fraction of the cost of flagship models.

Architecture and Open Design
At the heart of MiniMax M2’s performance is an ingenious Mixture-of-Experts (MoE) architecture. The model contains 230 billion total parameters but intelligently routes each query through only ~10 billion active parameters. This sparse activation means M2 can leverage a vast knowledge base when needed, yet achieve the speed and lower latency of a much smaller model in practice. The compact active set dramatically cuts memory use and inference time, enabling fast plan-act-verify loops for agents without “frontier-scale” computational costs. As VentureBeat notes, this design lets enterprises get near state-of-the-art results on just a handful of GPUs, making advanced AI far more accessible.
Key architectural features of MiniMax M2 include:
a) Sparse MoE with 10B active parameters: Only the most relevant experts are activated per token, reducing compute and tail latency while preserving high intelligence.
b) Ultra-Long Context Window: It handles up to 204,000 tokens of context (≈150,000 words) in input, plus ~131K tokens output – enough to fit entire codebases or documents. This industry-leading context (expandable toward 1 million tokens) matches or exceeds even top closed models like Google’s Gemini.
c) Interleaved “Thinking” Format: The model outputs its chain-of-thought inside special <think>…</think> tags, a transparent reasoning trace. Developers are expected to preserve these thinking tokens in the conversation history (not filter them out), because M2 trains with them and uses them to maintain coherence in multi-step solutions. This approach, similar to Anthropic’s Claude and other “visible reasoning” models, helps M2 plan complex actions and then provide a final answer with evidence.
d) Open-Source Availability: Not only are the M2 model weights openly published (MIT/Apache license), but the full stack is developer-friendly — it’s on Hugging Face for download, integrates with inference frameworks like vLLM and SGLang from day one, and even offers OpenAI/Anthropic-compatible APIs for easy adoption. (Notably, the license does forbid a few uses – e.g. using M2 to directly enhance other AI models – but for almost all applications it’s as permissive as standard MIT). MiniMax also launched a free demo platform and agent reference app, inviting the community to experiment.
This combination of massive knowledge, efficient use of compute, and open accessibility is what makes MiniMax M2 so compelling. As the MiniMax team puts it, M2 delivers “frontier-style coding and agents without frontier-scale costs,” hitting a sweet spot of performance vs. practicality.
Built for Coding: Performance on Programming Tasks
One of M2’s clear strengths is its prowess in coding. It was explicitly engineered for end-to-end developer workflows — meaning it can not only write code, but also read multi-file projects, execute code and observe outputs, then fix bugs in a tight loop. In evaluations that mirror real software engineering tasks, MiniMax M2’s results are impressive. For instance, on SWE-Bench Verified – a benchmark requiring solving real-world coding problems through multi-turn tool use – M2 scored 69.4%, which is on par with top proprietary models (OpenAI’s Claude Sonnet 4.5 scored 77.2% on that test) and higher than other open models of its generation. It also performed strongly on Terminal-Bench (46.3% pass rate on complex command-line coding challenges) and a challenging Multi-SWE-Bench suite (36.2%) covering multi-step software tasks. These numbers indicate an ability to handle tasks a developer might face in a live coding session or CI/CD pipeline.
Developers who tried M2 in practice noted its knack for multi-file editing and test-driven development. It can autonomously engage in a “coding-run-debug” loop: writing code, running it to catch errors, and patching mistakes – all within a single session. This makes it an effective AI pair programmer. In fact, according to independent benchmarks aggregated by Artificial Analysis, MiniMax M2 achieves near-top scores in coding competitions: for example, it solves competitive programming problems nearly as well as GPT-5. M2’s score on the LiveCodeBench challenge is around 83%, essentially matching the best closed models (GPT-5 ~85%) and edging out models like Anthropic’s Claude 4. This is corroborated by reports on similar coding benchmarks for its peers – Zhipu’s GLM-4.6, another code-focused model, also scores in the low 80s on LiveCodeBench. In short, M2 can generate correct, functional code for complex problems at a success rate previously limited to the likes of GPT-4/5.

Perhaps even more telling is the quality of code it produces. Observers noted that M2 and its competitors not only get the logic right, but also the style. A tech writer reviewing GLM-4.6 (which M2 rivals in code ability) noted its code outputs “aren’t just syntactically correct but more aligned with human expectations of design,” requiring less manual cleanup for things like front-end web code. MiniMax M2 shows similar polish. It consistently passed front-end coding tests, and MiniMax claims it can handle “entire codebases and multi-file projects without losing coherence” thanks to the huge context window. This means it can, for example, take in a whole React application and modify multiple files correctly — a previously daunting task for LLMs.
Real-world coding anecdotes further illustrate these capabilities. Users of Kimi K2 (a competing open model) have described how these new models can build working software from scratch. One tester prompted K2 to “build a Space Invaders game in HTML/JavaScript,” and the model generated a fully functional game in one go. Others had it produce complex web UI layouts (like replicating a macOS-style interface with interactive elements) purely from text instructions. MiniMax M2, with similar tool-using skills, can be leveraged in IDE plugins to debug code live or generate web designs on the fly. Essentially, tasks that blend programming with creative or design elements – from front-end web design to full-stack debugging – are now within the competence of these models.
To put the coding performance in perspective, consider how MiniMax M2 compares with its peers on a key coding benchmark and a key math benchmark:
Mathematical Reasoning and Problem Solving
Beyond coding, MiniMax M2 demonstrates robust general reasoning skills, including math and logic – though here it faces stiffer competition from other models specialized in these areas. On the AIME 25 exam (a notoriously difficult math contest), M2 achieves about 78% accuracy. By typical standards this is an outstanding result — it suggests the model can solve complex high school olympiad problems that stump most humans. However, the very latest open models have pushed even further on math. GLM-4.6, for instance, scored 93.9% on AIME-25 under evaluation, and Moonshot’s Kimi K2 in its “Thinking” variant reached 94–99% on AIME when allowed to use external calculation tools. In fact, K2 Thinking with a Python tool achieved 99.1% on that test, essentially near-perfect math performance. This indicates that M2, while very capable, could be a notch behind the absolute top-tier in pure math reasoning — likely because MiniMax optimized it more for coding+agents, whereas rivals like K2 and GLM did extra reinforcement learning specifically on step-by-step math problem solving.
That said, MiniMax M2’s approach to reasoning is quite advanced. The model is inherently an “interleaved thinking” model, meaning it was trained to generate explicit reasoning steps (<think>… tags) as it works through a problem. This is similar to how a person might scribble calculations on scratch paper. Because of this, M2 can tackle multi-step problems more reliably, provided the user (or calling application) preserves those scratch steps between turns. For example, on Humanity’s Last Exam (HLE) – a benchmark of extremely hard questions across disciplines – M2 scored 31.8% with tool use, significantly higher than many models that don’t show their reasoning. It outperformed GPT-4 (Claude 4) on that test and was only a bit behind GPT-5. M2’s score indicates it could answer roughly one in three “last exam” questions correctly using its reasoning and external tools, which is impressive given these questions are designed to stump advanced AI. However, the new Kimi K2 Thinking model pushed this further to 44.9% on HLE with tools — a new state-of-the-art. This again highlights how additional training on reasoning and allowing hundreds of tool calls (which K2 is tuned for) can boost performance on the hardest problems.
“Thinking vs. non-thinking” modes: It’s important to note that evaluations can differ depending on whether a model is allowed to use its chain-of-thought and tools. Many models now have distinct modes or settings: e.g. OpenAI’s GPT-5 can run in a special “thinking” mode that uses more internal deliberation (and even parallel chains) for tough queries. Similarly, Kimi K2 comes in two flavors – the standard “Instruct” model (direct answer) and the K2 Thinking model that interleaves reasoning and tool use. The difference is huge: in one report, base K2 solved only ~50% of AIME questions, but K2 Thinking solved 94% by showing its work. DeepSeek’s models also evolved in this way: their earlier V3 model gave direct answers, while the R1 model was a reasoning specialist; the latest DeepSeek-V3.1 merged both and can switch to a chain-of-thought mode via prompting. MiniMax M2, by design, always operates in a “thinking” mode (it always emits <think> steps). So when comparing models, one has to ensure we compare their best modes. With all models in full reasoning mode, the gap between MiniMax M2 and the top open models narrows on many tasks — for example, on math word problems or logical puzzles, M2 can often reach near top-tier performance given its strong training and huge context (for incorporating formulas or reference text). Still, the very latest models like K2 Thinking do hold a consistent edge on deep reasoning benchmarks, as evidenced by K2’s slight leads on tasks like HLE, AIME, and a suite of agent reasoning tests.
In practice, this means that for complex analytical tasks, M2 is extremely capable, but if you throw the hardest math olympiad or logic puzzle at it, an advanced user might get better results by enabling tool-use (e.g. letting M2 run Python code or search the web within its answer). It’s encouraging that M2 supports that out-of-the-box: the developers provide a Tool-Calling Guide and demonstrate M2 solving problems by writing and executing code during inference. This kind of automated tool use is exactly how K2 and GLM achieve those 95%+ scores. In fact, GLM-4.6’s report noted that with tool use enabled, it boosted its AIME score from ~94% to 98.6%, nearly eliminating errors. We can expect MiniMax M2 to show a similar jump when integrated with a calculator or code runner — as one commentator put it, “AIME is the new GSM8k” for these models, meaning these once-impossible math contests have essentially been mastered by letting the AI think step-by-step and double-check via tools.
Agentic Tool Use and Web Tasks
MiniMax M2’s tagline is a model for “Max coding & agentic workflows,” and indeed one of its standout features is how well it performs as an AI agent. By “agent” we mean an autonomous AI that can plan a multi-step solution, call external tools or APIs (like search engines, shell commands, or code interpreters), and adjust its plan on the fly from the results. M2 was explicitly designed for this: its plan→act→verify loop is baked into the architecture, and the model was trained on agentic data where it had to interact with a simulated environment. The result is that M2 can handle very long, complex action sequences with surprising robustness. For example, in MiniMax’s internal tests, M2 could control a web browser to perform research-intensive tasks (in benchmarks like BrowseComp) and a shell to execute scripts (in Terminal-Bench) significantly better than previous open models. It scored 44.0% on BrowseComp (English) and 48.5% on BrowseComp-ZH (Chinese), which means it successfully navigated and answered roughly half of the web research challenges — far above most models, which often fail such tasks entirely. (Notably, GPT-5 scored 54.9% on that same BrowseComp test, so M2 was closing in on the latest GPT’s capability for web navigation.) On Terminal-Bench, which involves solving problems by running shell commands and reading files, M2 achieved 46.3%, comfortably beating Claude 4’s score (36.4%) and nearly reaching Claude 4.5 (50%).
What’s even more impressive is how resilient and efficient M2 is in these scenarios. Evaluators observed that M2 would gracefully recover from errors during tool use — for instance, if a web query failed or code threw an exception, M2 could analyze the <think> trace, adjust the approach, and continue without giving up. Thanks to its modest active size, it doesn’t exhaust the context window or run up huge token bills while doing so. In fact, one benchmark noted M2 used ~15% fewer tokens on average than an earlier model for the same agent tasks, making it faster and cheaper to run. MiniMax highlights that keeping activations around 10B parameters yields “faster feedback cycles” in loops like “browse–retrieve–cite” when doing research. In enterprise terms, this means you can have more agent instances running concurrently on a given GPU budget — useful if you want, say, a fleet of document-search agents monitoring compliance data (one of the use cases MiniMax suggests).
However, the open-source race didn’t stop with M2. Within weeks, Moonshot AI’s Kimi K2 Thinking model arrived and upped the ante for agentic tasks. K2’s defining prowess is the ability to execute “hundreds of tool calls” in sequence without losing the thread. Early users pushed K2 through 200–300 step automation jobs (like iteratively searching dozens of sources and aggregating a report) and it remained coherent throughout. This essentially demonstrates superhuman diligence — something even GPT-4 often struggled with due to context limits or loss of focus. K2 Thinking’s published scores on agent benchmarks are now the highest on record: for BrowseComp it hit 60.2%, dramatically surpassing M2’s 44% and even beating GPT-5 (54.9%). On a financial info-retrieval task (FinSearchComp) it was on par with M2. And on τ²-Bench — a test of tool-augmented reasoning — M2’s very strong 77.2 was actually eclipsed by K2’s 84.7 (in non-thinking mode). The takeaway is that K2 Thinking essentially stole the crown from M2 for agentic automation, by wide margins in some cases. VentureBeat noted this passing of the torch, saying K2 “vaulted past both proprietary and open competitors to claim the top position” on coding+agent benchmarks, surpassing the previous open-source leader MiniMax-M2.
That said, MiniMax M2 remains a formidable open agent in its own right, especially given its much smaller active size. Its performance is more than sufficient for many real applications. For example, one could deploy M2 today as an AI research assistant that reads the web: it has shown it can find “hard-to-surface sources” online and compile answers with citations. Or use it as an autonomous coder that fixes software bugs overnight: M2’s ability to integrate with dev tools (and its low latency) mean it can handle continuous integration tasks — as described in a use case where M2 autonomously fixed failing unit tests in a CI pipeline before a human even reviewed the code. These kinds of workflows were almost science fiction a year ago; now an open model like M2 can do them reliably. M2 is also being integrated into products — Microsoft even added MiniMax M2 to Azure’s AI Foundry, citing its strength in coding, multi-turn reasoning, and efficiency for scaling deployments.
MiniMax M2 vs Kimi K2, GLM-4.6, and DeepSeek-V3.2
It’s illuminating to compare MiniMax M2 with its contemporary peers, as each represents a different approach at the cutting edge of open AI in 2025:
- MiniMax M2 (10B active / 230B total): Focused on coding and agent use, it launched as the top open model on composite intelligence (AA Index score 61). It pioneered the interleaved reasoning format with persistent <think> traces and delivered near-frontier performance in coding and tool use without requiring massive compute to run. M2’s strengths are its balanced skills (it has no major weak spot across coding, math, reasoning, etc. — earning it the “generalist” #1 spot among open models) and its practicality (fast inference, permissive license, API compatibility). Its main limitation is simply that it’s been leapfrogged on a few benchmarks by newer models that threw even more data/scale at the problem.
- Kimi K2 (32B active / 1T total): Released by Moonshot AI in November 2025, K2 (Thinking version) is now arguably the most capable open model. It’s an MoE like M2 but with a far larger expert pool (1 trillion parameters) and a 256K token context. K2 is trained with heavy emphasis on step-by-step reasoning and tool use, including a joint RL stage where it learned to solve tasks by actually invoking tools in loops. It achieved state-of-the-art scores on many benchmarks: e.g. #1 on HLE and BrowseComp, and beating GPT-5 and Claude 4.5 on several coding and QA tests. In coding, K2 Thinking’s performance is within a hair of M2 (they both score ~83% on LiveCodeBench, and K2 is ~2 points higher on SWE-Bench). In math and reasoning, K2 Thinking currently leads — effectively tying GPT-5 on tough math like AIME/HMMT. K2’s strengths are its raw power and reasoning depth — it has the highest scores across the board among open models — and its transparency, as it outputs a reasoning_content field similar to M2’s think traces. One notable innovation is K2’s use of INT4 quantization during training (QAT), making it twice as fast at inference with no loss in accuracy. This gives it a speed edge, even over M2, despite the larger size. The only downsides to K2 are heavier resource requirements (1T model is ~600GB at full precision, though 4-bit cuts that down), and the fact that it literally came after M2 — a reminder that the open model race is moving extremely fast.
- GLM-4.6 (≈32B dense / 355B total†): Part of the GLM series from Zhipu (China’s Zai group), GLM-4.6 is a dense transformer blended with some sparse techniques (it’s not as explicitly MoE as M2/K2, but uses advanced training tricks). Branded a “superior coding” model, GLM-4.6 was explicitly tuned for software development scenarios. It delivered a huge jump over its predecessor (GLM-4.5) on coding benchmarks — e.g. LiveCodeBench v6 went from 63.3 to 82.8, nearly matching Anthropic’s Claude Sonnet 4. It also improved in mathematical reasoning (scoring ~94 on AIME) and supports a 200K token context for long projects. GLM’s key strength is coding fluency: testers noted it often produces cleaner and more polished code than other models, even for front-end web tasks. It’s integrated into many Chinese coding assistant products and offered at a low price via Zhipu’s API (they advertise “9/10ths of Claude at 1/7th the price”). GLM-4.6 was set to be open-sourced under MIT as well, which would make it another major open competitor. While it may not have the multi-tool autonomy of M2 or K2 (it can use tools, but K2/M2 really specialize there), GLM-4.6 is possibly the best pure coder in terms of single-shot code generation and debugging. It slightly lags M2/K2 on agentic benchmarks (for example, M2 outscored it on Multi-SWE and browse tasks), but for code writing and general QA it’s top-tier.
- DeepSeek V3.2 (37B active / ~671B total): DeepSeek is another prominent open model line from China, known for pioneering “reasoning models” early (their DeepSeek-R1 was one of the first open models to explicitly output reasoning steps). DeepSeek-V3.2, released in late 2025, takes a slightly different approach: it introduces Sparse Attention (DSA) to improve efficiency on long contexts. Its performance is roughly on par with DeepSeek-V3.1 (which was already very strong, ~GPT-4.5 level on many tasks), but V3.2 is much cheaper to run — it was touted as “the cheapest model ever that still packs serious power”. Like M2 and K2, it’s a hybrid MoE (671B total, 128K context) and it can operate in either direct answer mode or reasoning mode depending on how you prompt it. DeepSeek’s strength is efficiency and stability: they focused on eliminating training instabilities (using a technique called MuonClip) and reducing hallucination rates. It might not beat M2 or K2 on absolute scores – for example, DeepSeek-V3.2’s BrowseComp ~40% vs M2’s 44%, and AIME ~88 vs K2’s 94 – but it’s very close, and likely less resource-intensive for similar output. DeepSeek also has an excellent community following; many developers use its models for self-hosted setups due to the permissive MIT license and the active support (guides for BentoML, RedHat, etc. appeared immediately). In summary, DeepSeek-V3.2 is a strong all-rounder with an emphasis on cost-effective deployment — an attractive option if one needs high performance on tasks like math, coding, and multi-turn QA but cannot afford the absolute newest models’ runtime costs.
Finally, it’s worth noting that all these models share a common trend: open-source AI is catching up with – and in some cases surpassing – the closed models. Only a few months ago, it was assumed that GPT-4 or Claude had an enduring lead. But with MiniMax M2, then Kimi K2, and others, the gap has essentially collapsed for high-end reasoning and coding. By the time of K2’s release, Moonshot proudly pointed out their open model was outscoring OpenAI’s GPT-5 and Anthropic’s Claude 4.5 on several key benchmarks. This rapid leapfrogging (M2 was top open for a short period until K2 overtook it) underscores how competitive the AI landscape has become, driven by collaboration and transparency in the open-source community.
In conclusion, MiniMax M2 represents a milestone in the AI world: a compact, efficient model that delivers frontier-level coding assistance and autonomous reasoning to anyone with a few GPUs. As a tech journalist observing its impact, it’s clear M2 and its ilk are democratizing capabilities that recently belonged only to tech giants. A developer can now download an open model and have a conversational partner that debugs code, answers advanced math questions, or conducts research on their behalf, with an intelligence approaching the best of Silicon Valley’s closed systems. MiniMax M2 specifically showcased how careful architectural choices — like MoE sparsity and interleaved thinking — can yield a model that is both high-performing and practical. It’s fast, cost-effective (MiniMax says about 8% the API cost of Claude for the same tasks), and flexible to integrate.
That said, the story doesn’t end with M2. The open AI ecosystem is evolving at breakneck speed — MiniMax M2’s reign at the top was brilliant but brief, as competitors swiftly incorporated its innovations and added more. The good news is that this competition only pushes things forward. MiniMax M2 remains an “innovator model” that proved what’s possible, and it continues to be a robust choice for anyone needing an all-around coding and reasoning assistant. Meanwhile, the ideas it championed (like visible reasoning and scalable context windows) are becoming standard in the next generation of models. For developers and enterprises, the takeaway is exciting: open-source AI is no longer one step behind — it’s right at the cutting edge. MiniMax M2’s success, followed by K2’s breakthrough, shows that a talented team with the right strategy can produce an open model that truly rivals the best of Big Tech in many domains. The race is on, and ultimately users and researchers benefit from this fast-paced innovation. MiniMax M2 has opened the door to a future where AI assistants for coding, math, web design, and beyond are both high-quality and widely accessible — a future that is now rapidly becoming reality.
Learn more about MiniMax M2 Review and Comparison With Open-Weight Rivals