
We conducted a preregistered study comparing MFA-trained expert writers with three frontier AI models: ChatGPT, Claude, and Gemini in writing up to 450 word excerpts emulating 50 award-winning authors’ (including Nobel laureates, Booker Prize winners, and young emerging National Book Award finalists) diverse styles.
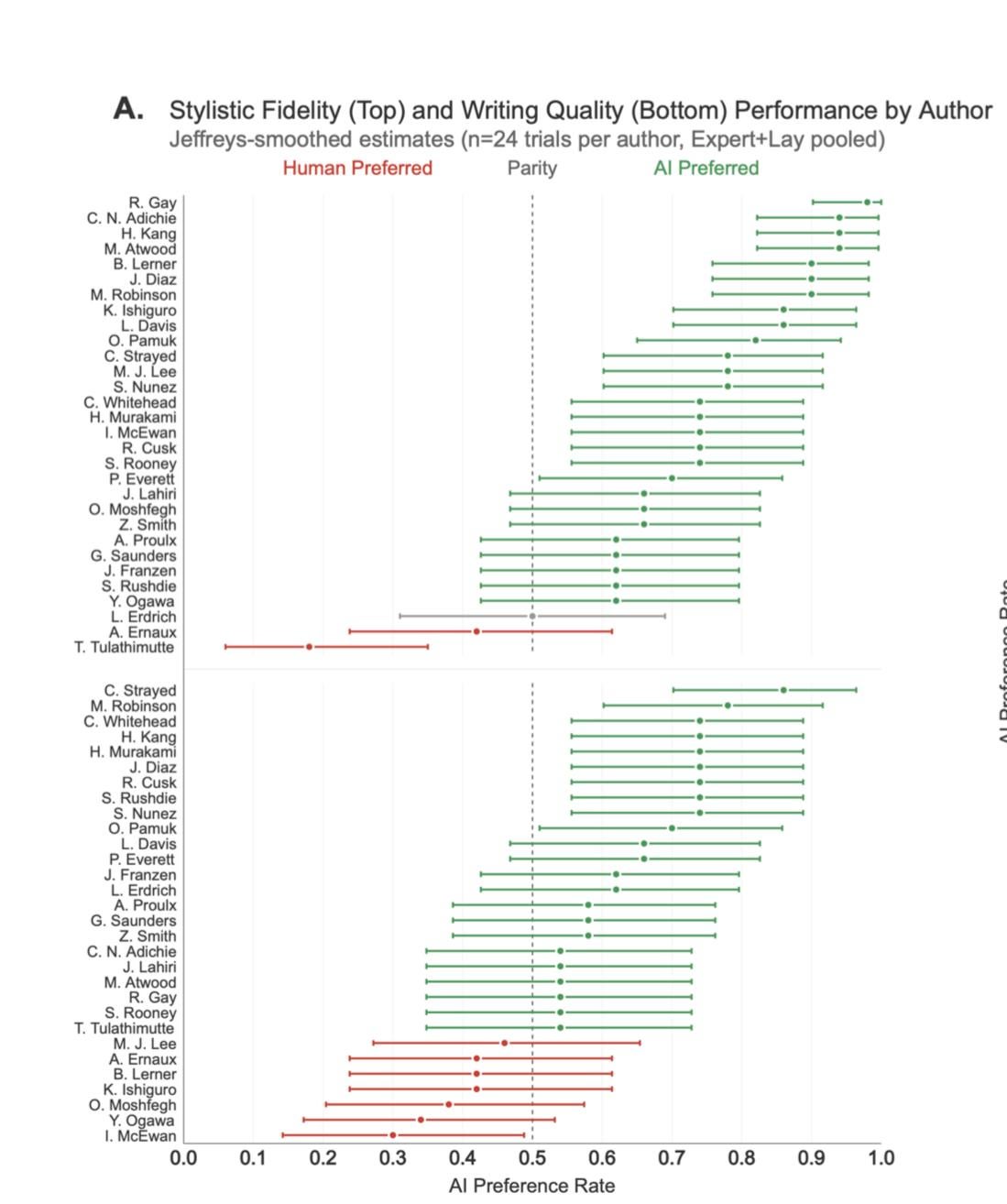
In blind pairwise evaluations by 159 representative expert (MFA candidates from top U.S. writing programs) and lay readers (recruited via Prolific), AI-generated text from in-context prompting was strongly disfavored by experts for both stylistic fidelity and writing quality but showed mixed results with lay readers.
However, fine-tuning ChatGPT on individual author’s complete works completely reversed these findings: experts now favored AI-generated text for stylistic fidelity and writing quality, with lay readers showing similar shifts. These effects are robust under cluster-robust inference and generalize across authors and styles in author-level heterogeneity analyses.
The fine-tuned outputs were rarely flagged as AI-generated (3% rate versus 97% for in-context prompting) by state-of-the-art AI detectors.
Mediation analysis reveals this reversal occursbecause fine-tuning eliminates detectable AI stylistic quirks (e.g., clich´e density) that penalize in-context outputs, altering the relationship between AI detectability and reader preference.
While we do not account for additional costs of human effort required to transform raw AI output into cohesive, publishable novel length prose, the median fine-tuning and inference cost of $81 per author represents a dramatic 99.7% reduction compared to typical professional writer compensation.