Despite significant advancements in large language models (LLMs), the ability to reliably perform multi-step reasoning continues to be a central and enduring challenge for the field. Though methods such as sophisticated prompting and fine-tuning have improved performance, models still underperform when the required reasoning path is obscure or when a lack of granular feedback (sparse rewards) makes learning the correct steps difficult.
This struggle exposes a deeper truth: most existing training paradigms, whether Supervised Fine-Tuning (SFT) or Reinforcement Learning with Verifiable Rewards (RLVR), were never designed to truly teach how to think. They teach what to output.
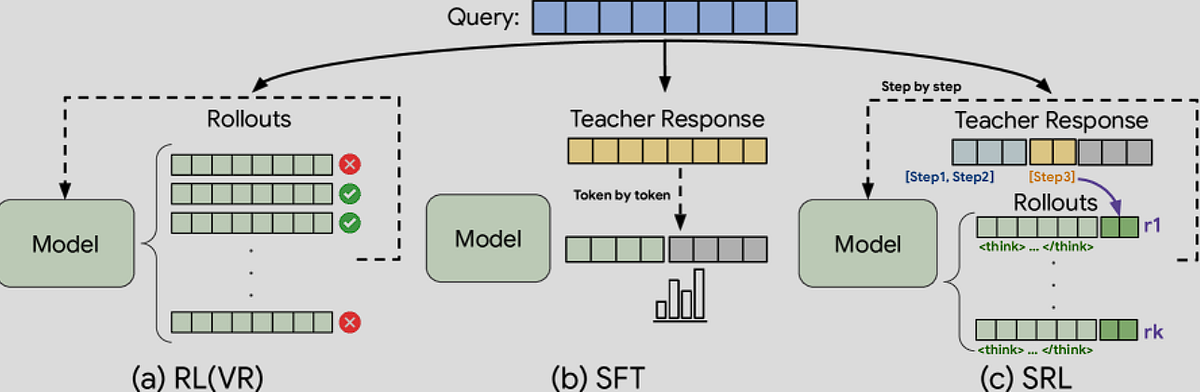
To bridge this cognitive gap, a new framework: Supervised Reinforcement Learning (SRL) reimagines model training as a structured reasoning process, where a model learns to act step-by-step like a human solving a problem.

The Root of the Problem: Sparse Rewards and Overfitting
LLMs, by nature, predict the next word based on statistical likelihood, not logical necessity. Traditional training methods in tasks like mathematical reasoning or…
{kind=link}