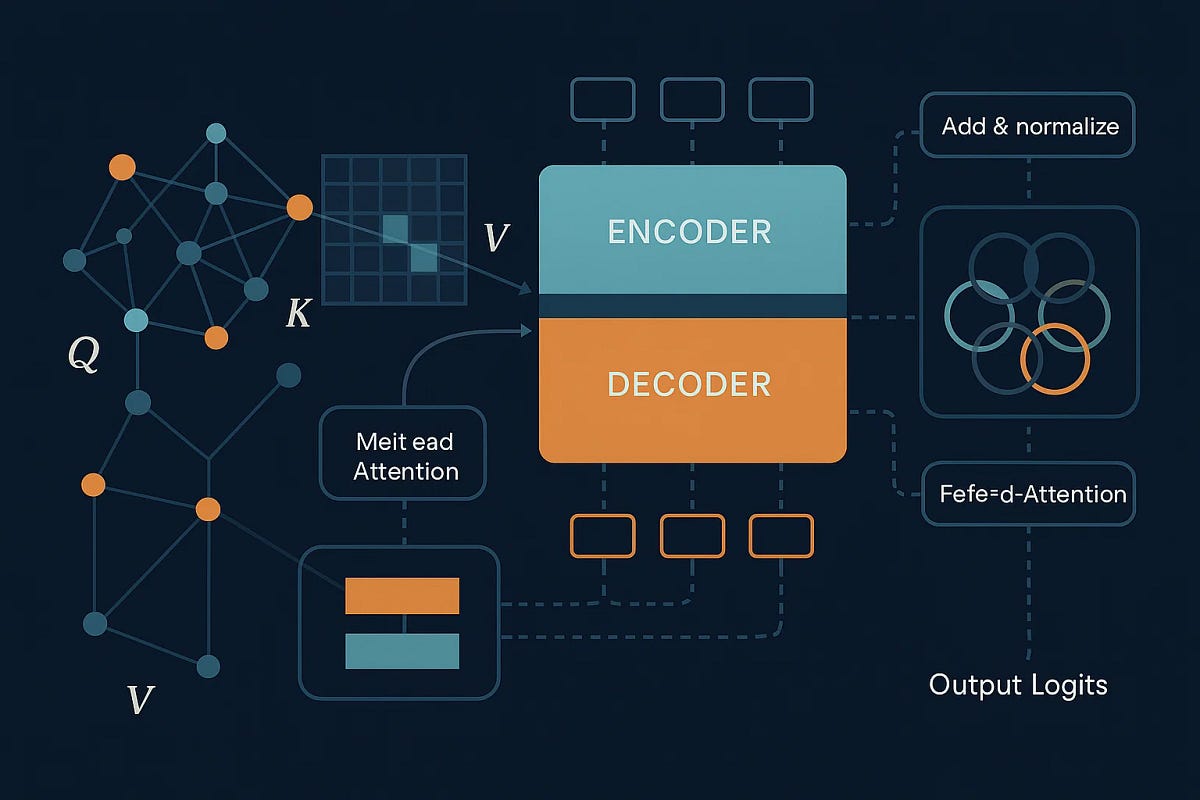
In June 2017, eight researchers at Google published a paper that would fundamentally reshape artificial intelligence. “Attention Is All You Need” introduced the Transformer architecture , a deceptively simple idea that now powers every major language model you interact with today.
Before this paper, if you wanted to build a translation system or chatbot, you needed recurrent neural networks (RNNs) or convolutional networks. These were slow, hard to train, and struggled with long sequences. The Google team, led by Ashish Vaswani, proposed something radical: what if we ditched recurrence entirely and relied solely on attention mechanisms?
The Core Innovation: Self-Attention
The breakthrough was the self-attention mechanism. Instead of processing words sequentially, the Transformer looks at all words simultaneously and figures out which ones matter for understanding each word.
Here’s the mathematical foundation:
import numpy as np
def scaled_dot_product_attention(Q, K, V):
"""
Q: Query matrix (seq_len, d_k)
K: Key matrix (seq_len, d_k)
V: Value matrix (seq_len, d_v)
"""
d_k = Q.shape[-1]
# Calculate attention scores
scores = np.matmul(Q, K.T) / np.sqrt(d_k)
# Apply softmax…